RAG知识库
- 教育场景:AI 针对学生的薄弱环节提供个性化辅导和学习资源推荐。
- 电商场景:AI 根据用户购物历史和偏好推荐适合的商品,并提供智能客服支持。
- 法律咨询:AI 能解答法律疑问,提供相关法规信息,节省律师时间和成本。
- 金融场景:AI 为客户提供个性化理财建议,风险评估和投资组合优化方案。
目前知识获取有两个方面
- 互联网
- 知识库
但是AI可能回复错误内容、不按照指定内容回复,所以我们读取自己的知识库,让AI根据已有的知识库回复,而不回复其余内容。可以使用AI主流技术:RAG知识库。
RAG概念
RAG(Retrieval-Augmented Generation 检索增强生成),这是一种结合了信息检索(Information Retrieval, IR)与文本生成(Text Generation)的混合方法,旨在提高生成模型输出的相关性和准确性。
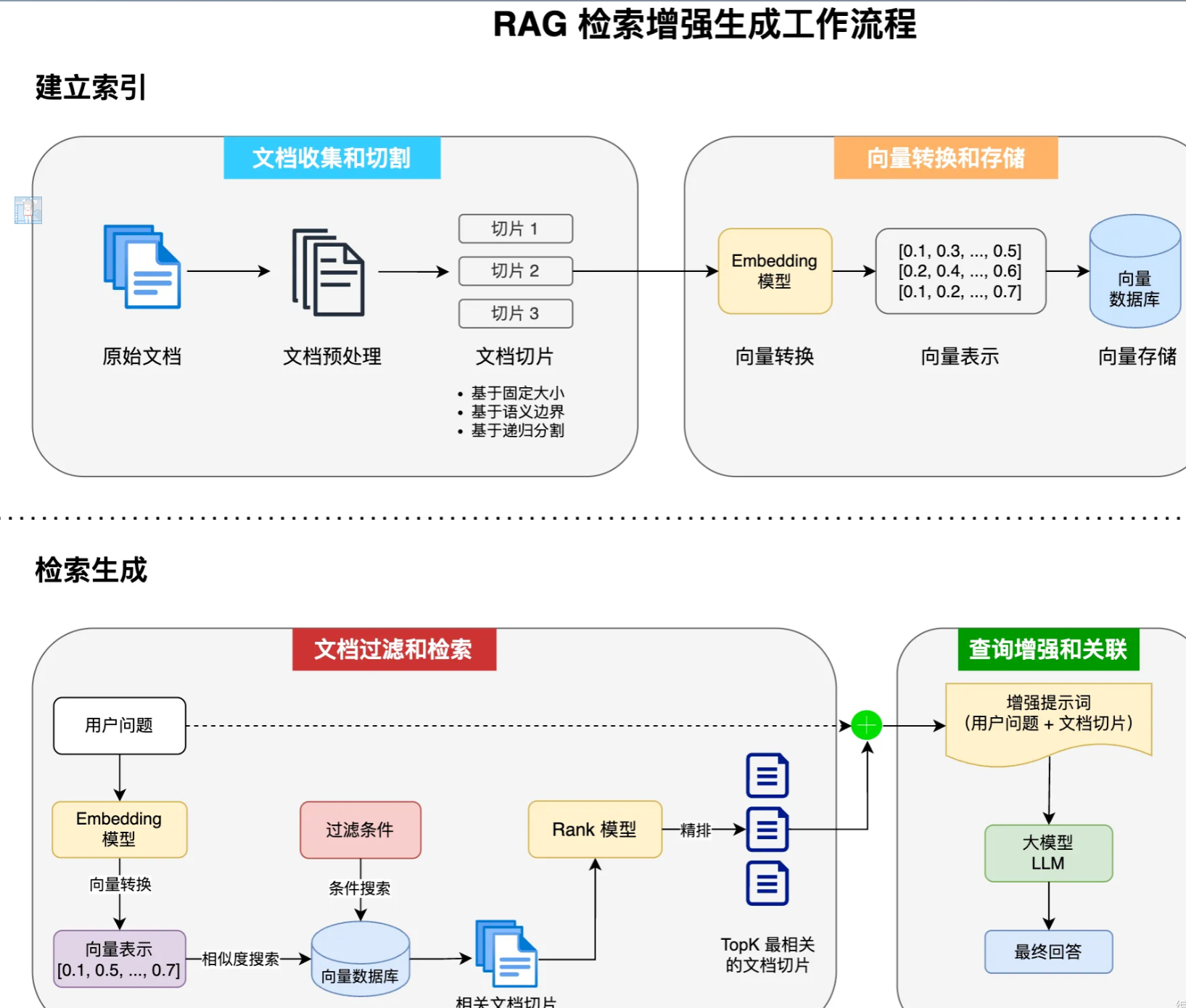
RAG工作流程
- 文档收集和切割
- 向量转换和存储
- 文档过滤和检索
- 查询增强和关联
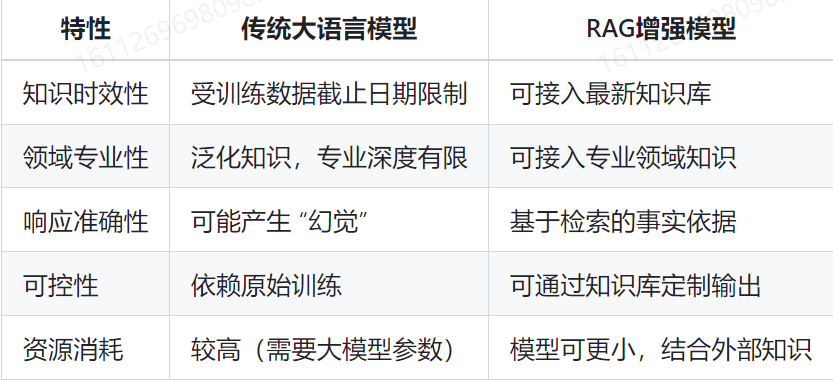
1. 文档收集和切割
文档收集:从各种来源收集原始文档
文档预处理:清洗、标准化文档结构
文档切割:将长文档分割成适当大小的片段(chunks)
- 基于固定大小(如512token)
- 基于语义边界(段落)
- 基于递归分隔策略
常用的方式是:根据段落和回车分隔
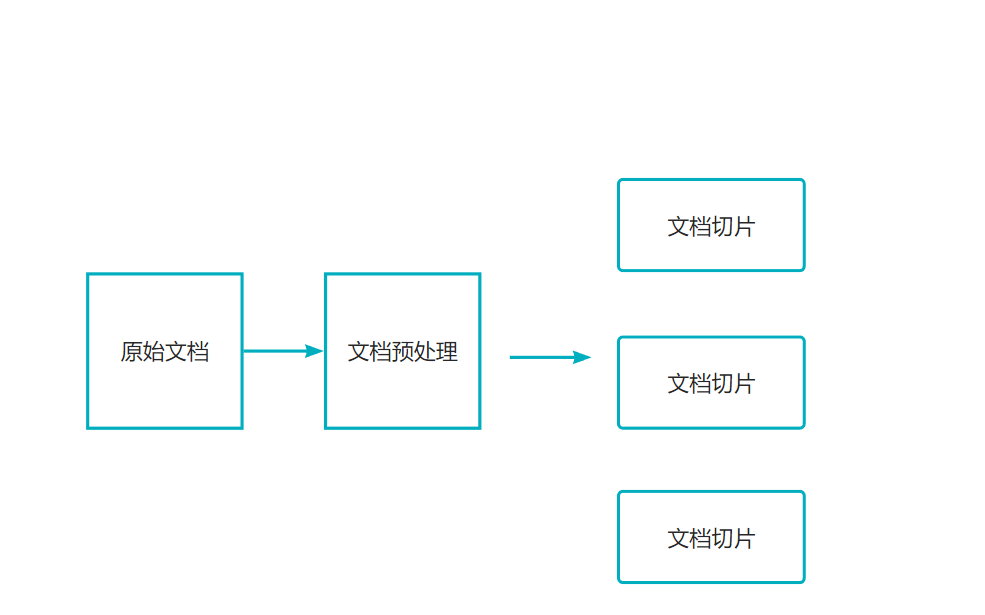
2. 向量转换和存储
向量转换:使用Embedding模型将文本转换为高维向量表示,可以捕获到文本的语义特征
向量存储:将生成的向量和对应文本存储到向量数据库,支持高效的相似性处理。
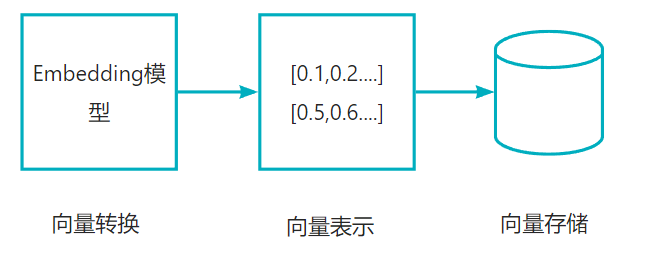
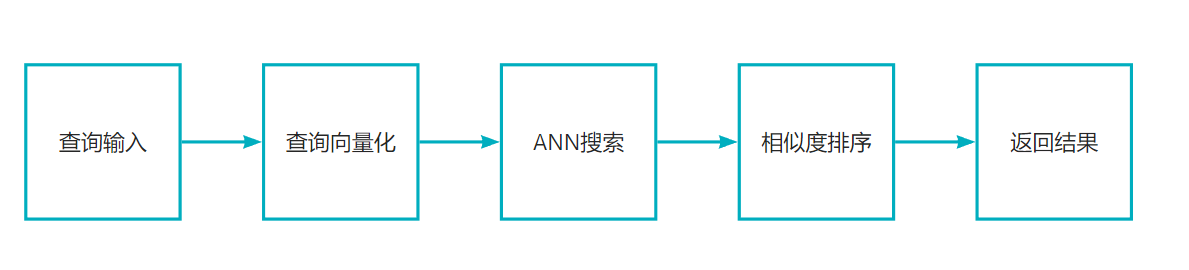
3. 文档过滤和检索
查询处理:将用户的问题也转换为向量表示
过滤机制:根据元数据、关键词、定义规则进行过滤
相似度搜索:在向量数据库中查找与问题向量最相似的文档块(余弦相似度、欧氏距离)
上下文组装:根据检索到的多个文档块组成连贯的上下文
4. 查询增强与关联
提示词组装:将检索到的文档和用户的问题进行增强组合
上下文融合:大模型增强提示生成回答
源引用:在回答中添加信息引用来源
后处理:格式化、摘要或其他处理优化最终输出

结合
RAG相关技术
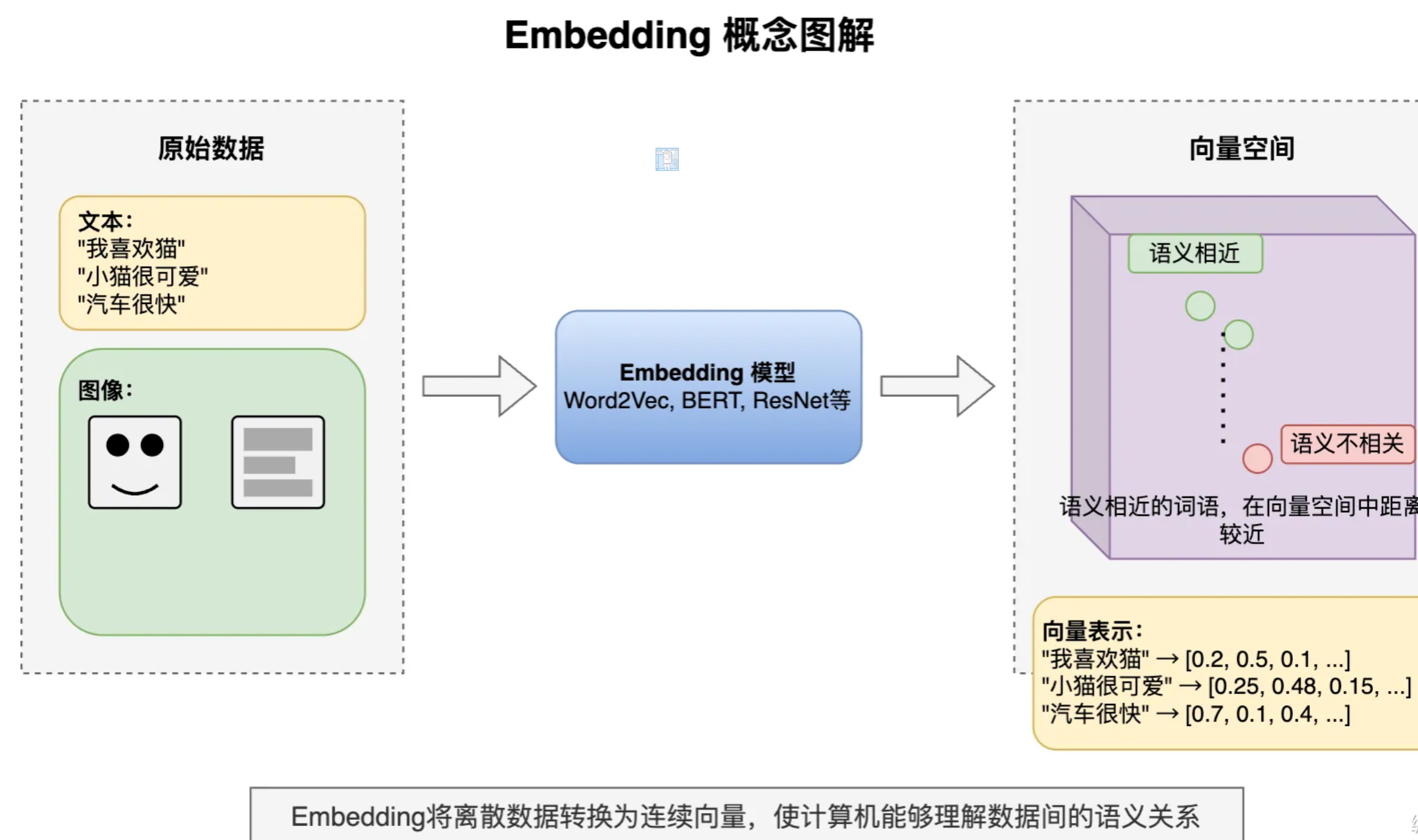
Embedding
Embedding 嵌入是将高维离散数据(如文字、图片)转换为低维连续向量的过程。这些向量能在数学空间中表示原始数 据的语义特征,使计算机能够理解数据间的相似性。
Embedding模型是执行这种转换算法的机器学习模型,如Word2Vec(文本)、ResNet(图像)等。不同的Embedding 模型产生的向量表示和维度数不同,一般维度越高表达能力更强,可以捕获更丰富的语义信息和更细微的差别,但同样占 用更多存储空间。
向量数据库
专门存储和检索数据的数据库系统。通过高效索引算法实现快速相似性搜索。向量数据的典型结构是一个一维数组,其中的元素是数值(通常是浮点数)。这些数值表示对象或数据点在多维空间中的位置、特征或属性。 腾讯云向量数据库

召回
召回是信息检索的第一阶段,目的是从大规模数据中筛选出可能相关的候选项子集,强调的是速度和广度,而不是精确度。
精排和Rank模型
精排这是信息检索的最后阶段,使用计算复杂度更高的算法,考虑更多的特征和业务规则,对于候选项进行更复杂、精细的排序。

Rank模型负责对召回阶段筛选出的数据进行精确排序,考虑多种特征评估相关性
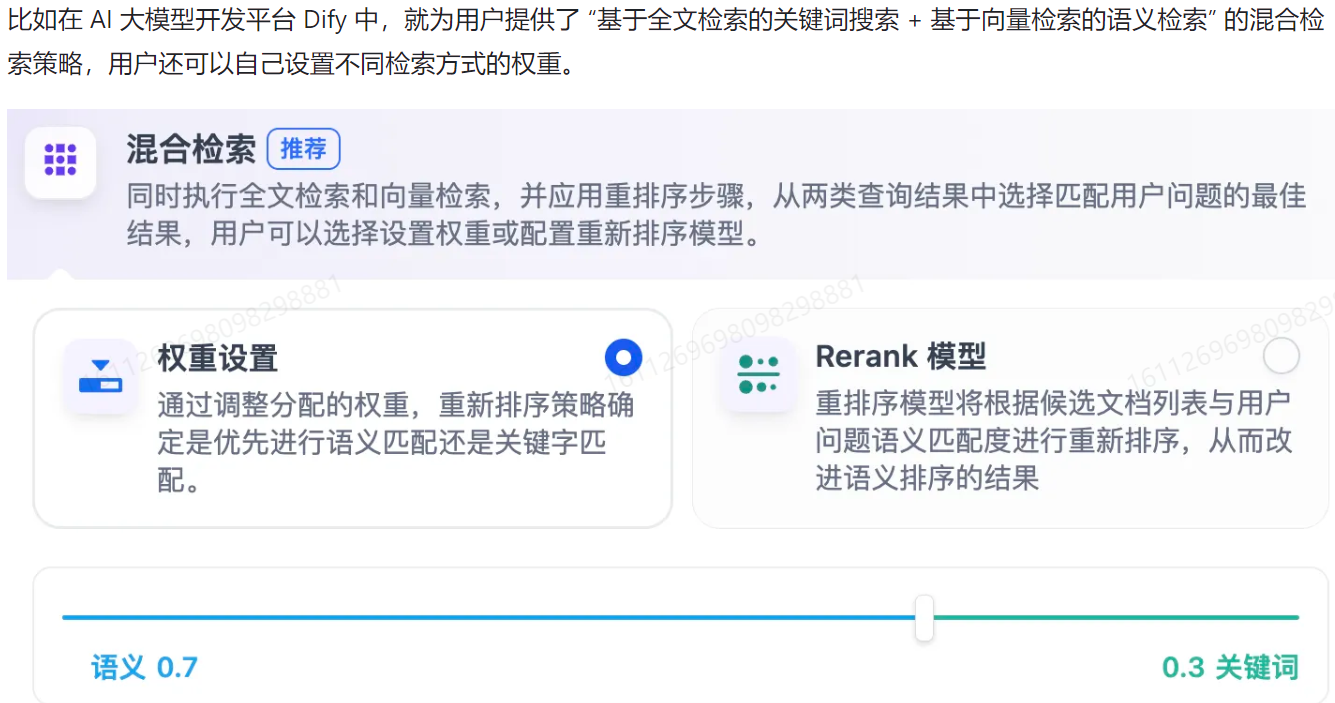
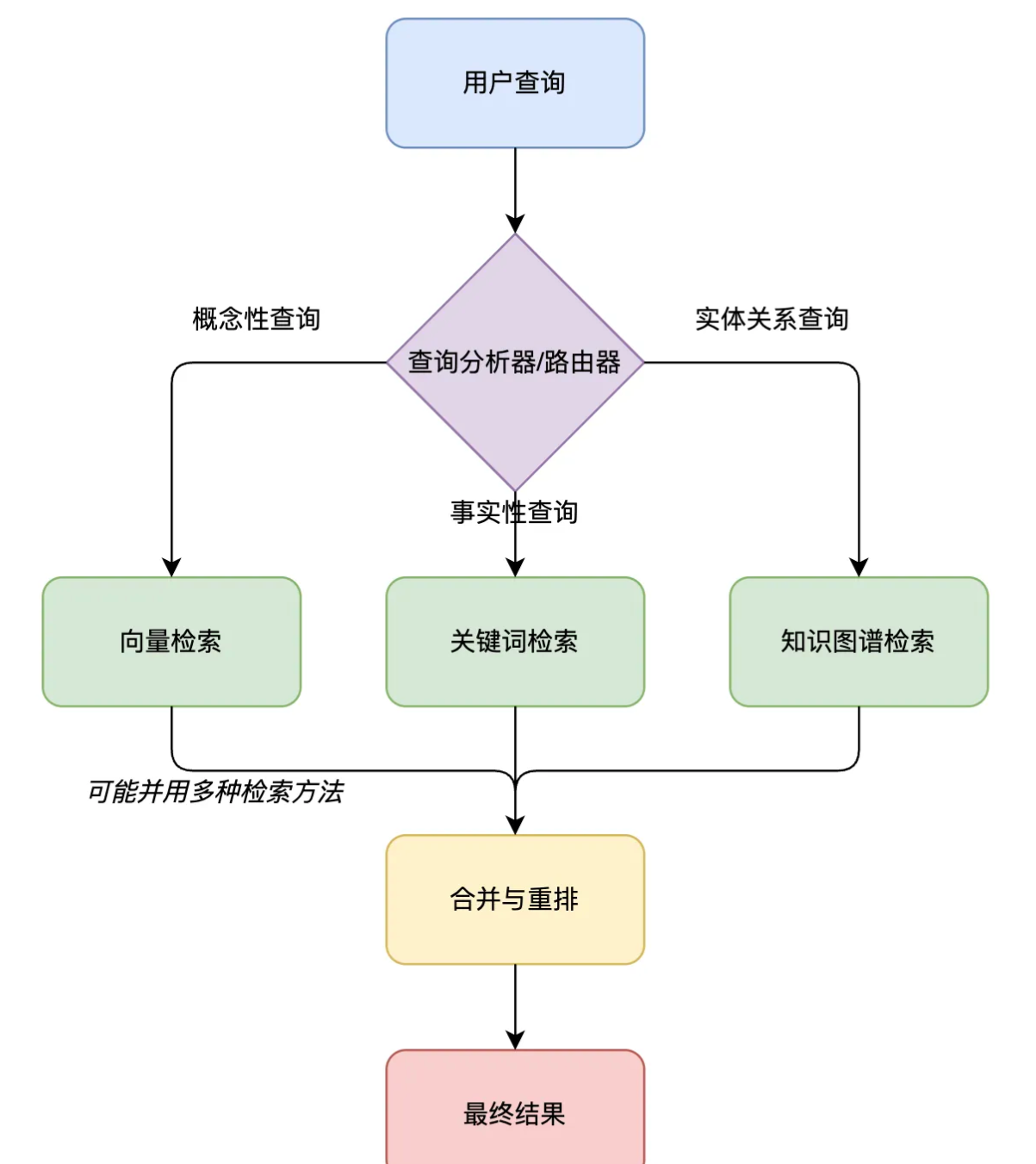
混合检索策略
结合多种检索方法,提高搜索效率。常见关键词、语义、知识图谱。
RAG开发
首先需要引入Spring AI相关组件,详情参考SpringBoot调用AI
1. 文档准备
自行准备文档
2. 文档读取
提取、转换和加载 (ETL) 框架是检索增强生成 (RAG) 用例中数据处理的主干。
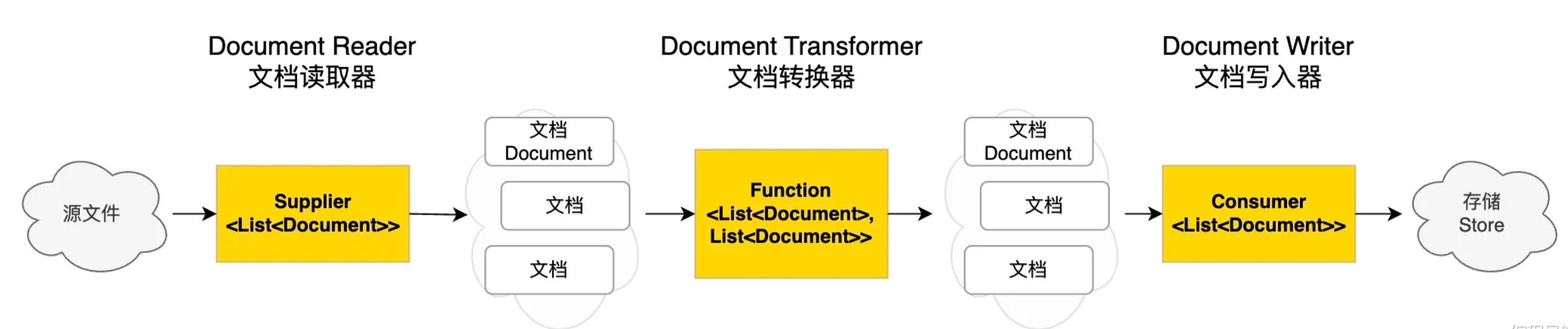
ETL三个主要组件
- DocumentReader:读取文档,得到文档列表
- DocumentTransformer:转换文档,得到处理后的文档列表
- DocumentWriter:将文档列表保存到存出中
- 引入依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-markdown-document-reader</artifactId>
<version>1.0.0-M6</version>
</dependency>- 读取文件
/**
* 读取指定位置文档到知识库
*/
@Component
@Slf4j
public class LoveAppMarkdownLoader {
private final ResourcePatternResolver resourcePatternResolver;
public LoveAppMarkdownLoader(ResourcePatternResolver resourcePatternResolver) {
this.resourcePatternResolver = resourcePatternResolver;
}
List<Document> loadMarkdown() throws IOException {
List<Document> allDocuments = new ArrayList<>();
try {
// 1. 读取本地文件
Resource[] resources = resourcePatternResolver.getResources("classpath:documents/**.md");
for (Resource resource : resources) {
// 2. 编写配置
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(true)
.withIncludeCodeBlock(false)
.withIncludeBlockquote(false)
.withAdditionalMetadata("filename", resource.getFilename())
.build();
MarkdownDocumentReader reader = new MarkdownDocumentReader(resource, config);
// 3. 存储文档列表
allDocuments.addAll(reader.get());
}
} catch (IOException e) {
throw new RuntimeException(e);
}
return allDocuments;
}
}3. 向量转换和存储
可以使用SimpleVector实现初始化向量数据库并且保存文档,以下是添加方法。
@Override
public void doAdd(List<Document> documents) {
Objects.requireNonNull(documents, "Documents list cannot be null");
if (documents.isEmpty()) {
throw new IllegalArgumentException("Documents list cannot be empty");
}
for (Document document : documents) {
logger.info("Calling EmbeddingModel for document id = {}", document.getId());
float[] embedding = this.embeddingModel.embed(document);
SimpleVectorStoreContent storeContent = new SimpleVectorStoreContent(document.getId(), document.getText(),
document.getMetadata(), embedding);
this.store.put(document.getId(), storeContent);
}
}SimpleVectorStore可以输入如下参数,每个重载方法里面都需要加入embedding,是从embeddingModel转换出来的向量。

/**
* VectorStore实现初始化向量数据库
*/
@Configuration
public class LoveAppVectorConfig {
@Resource
private LoveAppMarkdownLoader loveAppMarkdownLoader;
@Bean
VectorStore loveAppVectorStore(EmbeddingModel dashscopeEmbeddingModel) throws IOException {
//初始化
SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(dashscopeEmbeddingModel).build();
// 加载Markdown文件并添加到向量存储中
List<Document> documents = loveAppMarkdownLoader.loadMarkdown();
simpleVectorStore.doAdd(documents);
return simpleVectorStore;
}
}4. 查询增强
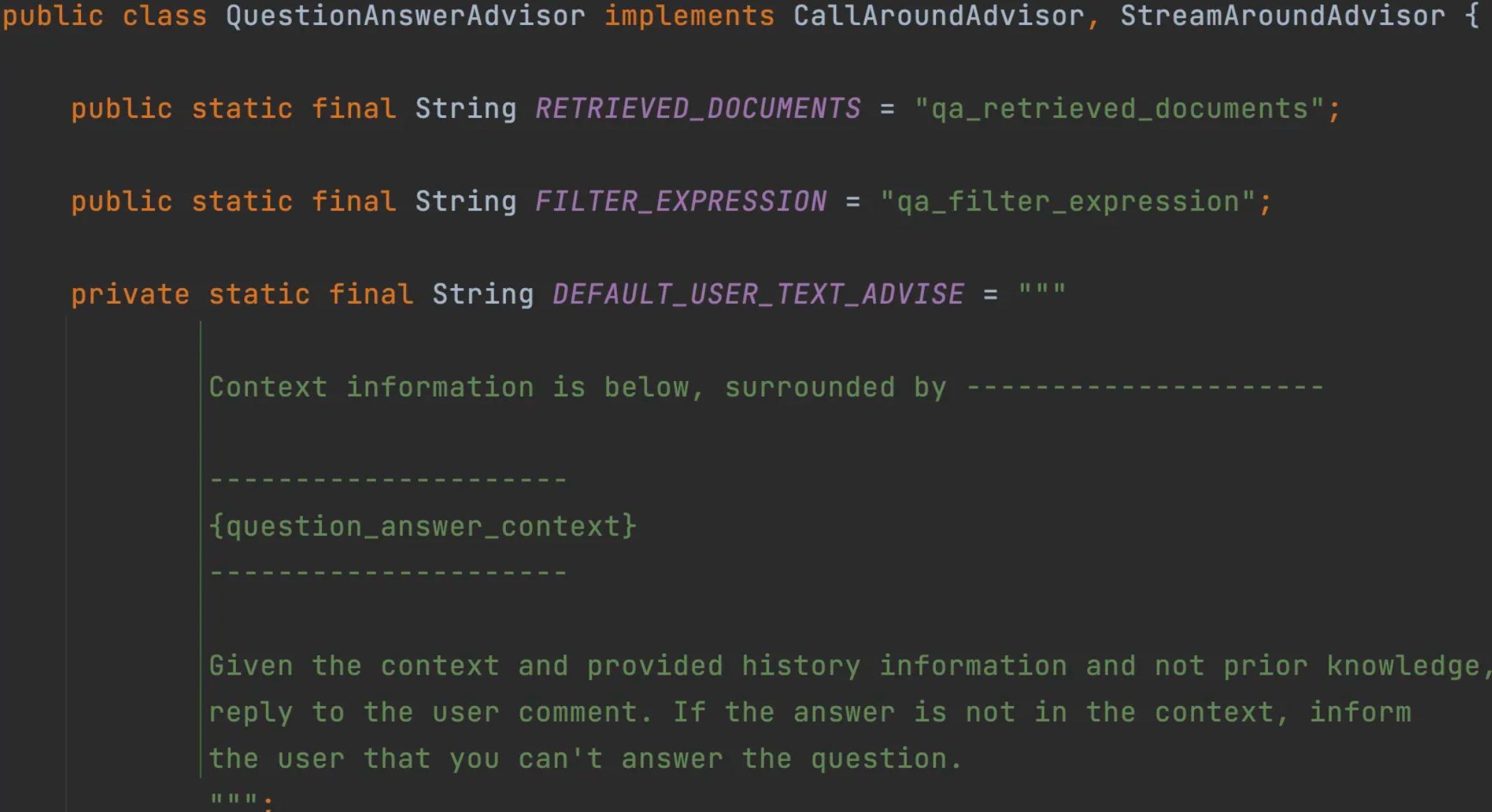
Spring AI 通过Advisor特性提供了开箱即用的RAG功能。主要是QuestionAnswerAdvisor 问答拦截器和 RetrievalAugme ntationAdvisor检索增强拦截器,前者更简单易用、后者更灵活强大。
查询增强的原理其实很简单。向量数据库存储着AI模型本身不知道的数据,当用户问题发送给AI模型时,QuestionAns werAdvisor 会查询向量数据库,获取与用户问题相关的文档。然后从向量数据库返回的响应会被附加到用户文本中,为模型提供上下文,帮助其生成回答。
@Resource
private VectorStore loveAppVectorStore;
public String doChatWithRAG(String message, String chatId) {
ChatResponse chatResponse = chatClient
.prompt()
.user(message)
.system(SYSTEM_PROMPT)
.advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId)
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 10))
.advisors(new MyAdvisors())
.advisors(new QuestionAnswerAdvisor(loveAppVectorStore))
.call()
.chatResponse();
String content = chatResponse.getResult().getOutput().getText();
log.info(content);
return content;
}
通过打断点方式我们可以看到每个文档块生成了多个向量集合,通过这些向量可以匹配出当前数据库符合用户提问的结果。
在读取Doucements时候,我们可以看到一篇文章被Spring AI切割成10个文档块,每个文档块有自己的向量集合。

阿里云RAG
录入数据库
选择阿里的原因是有Spring AI Alibaba兼容Spring AI,比较适用于java开发。
https://bailian.console.aliyun.com/?tab=app#/data-center
我们可以在官网看到阿里的知识库。
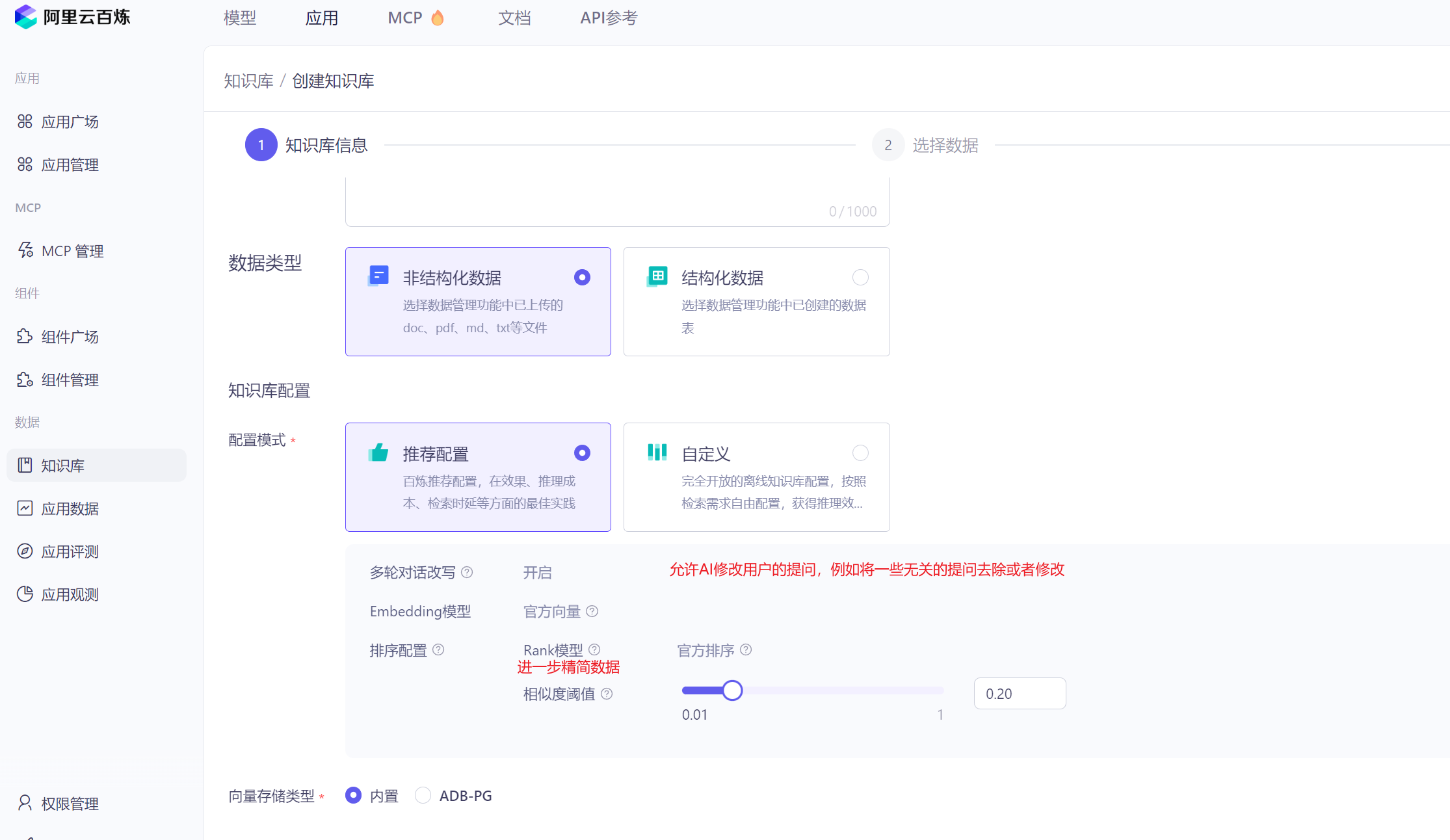
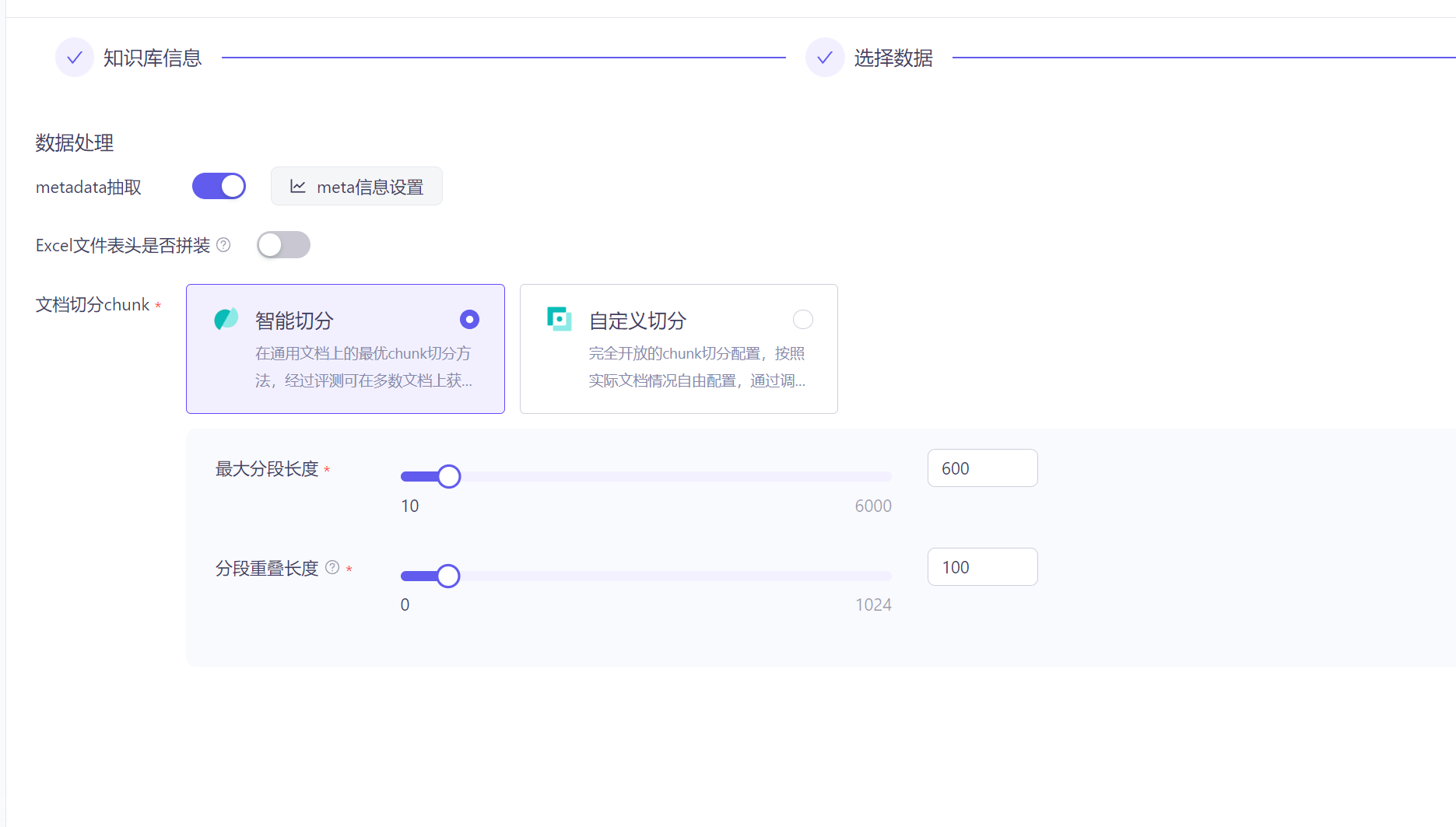
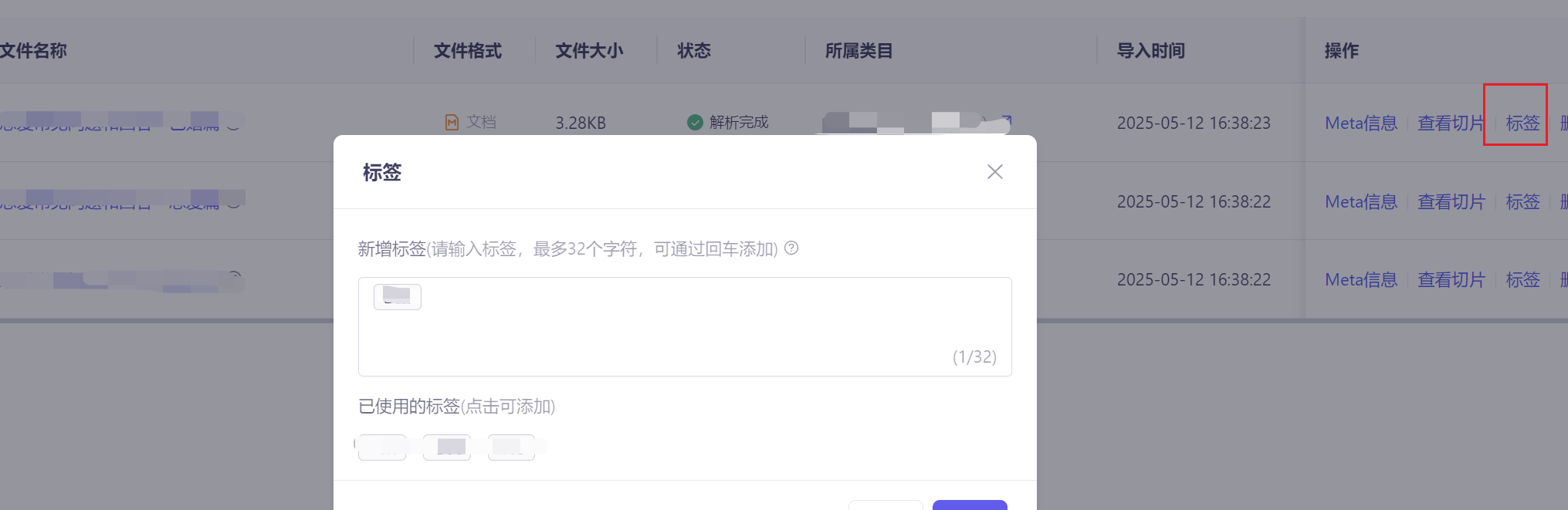
可以给不同的文档添加不同的标签,每个文档都可以创建对应的标签,在搜索的时候优先根据标签筛选出结果
前置数据库已经准备完成,后面可以阅读Spring AI Alibaba实现RAG数据库
RAG开发
var dashScopeApi = new DashScopeApi(System.getenv("DASHSCOPE_API_KEY"));
DocumentRetriever retriever = new DashScopeDocumentRetriever(dashScopeApi,
DashScopeDocumentRetrieverOptions.builder()
.withIndexName("spring-ai知识库")
.build());
List<Document> documentList = retriever.retrieve(new Query("What's spring ai"));官方示例只能进行简单的查询,我们可以使用Spring AI的Retrieval Augmented Generation(检索增强顾问)这就需要使用Spring AI提供的RAG Advisor ,可以绑定文档检索器、查询转换器和查询增强器,更灵活地构造查询。
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
.build();
String answer = chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user(question)
.call()
.content();@Configuration
@Slf4j
public class LoveAppAdvisorConfig {
@Value("${spring.ai.dashscope.api-key}")
private String dashScopeKey;
@Bean
public Advisor loveAppRagAdvisor() {
DashScopeApi dashScopeApi = new DashScopeApi(dashScopeKey);
DocumentRetriever documentRetriever = new DashScopeDocumentRetriever(dashScopeApi,
DashScopeDocumentRetrieverOptions.builder()
.withIndexName("xxx(阿里配置的知识库名称)")
.build()
);
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(documentRetriever)
.build();
return retrievalAugmentationAdvisor;
}
}即可在应用程序中加入Advisor
RAG核心特性
文档收集与切割(ETL)
文档收集和切割阶段,我们需要对知识库文档进行处理,其中涉及到提取、转换和加载 ,这个过程成为ETL( Extract, Transform, and Load)。
Document(文档)
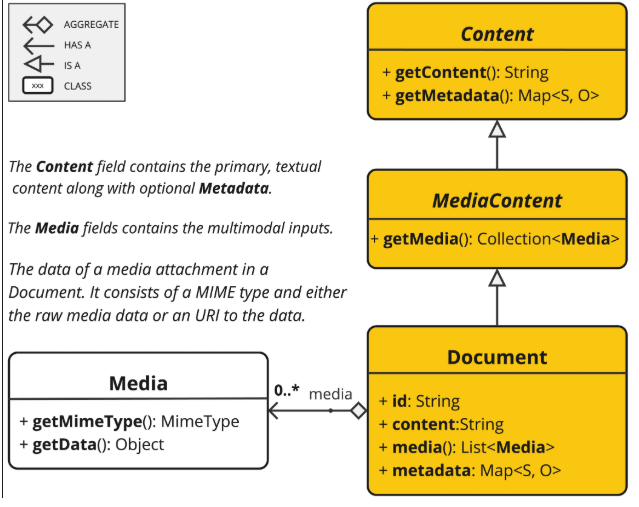
Document 类包含文本、元数据和可选的其他媒体类型,如图像、音频和视频。
ETL
ETL 管道有三个主要组件:
- 读取文档:使用DocumentReader从源数据加载文档。
- 转换文档:使用DocumentTransformer将文档转换为后续需要处理的格式,比如去除冗余信息、分词等等。
- 写入文档:使用DocumentWriter将文档保存到指定存储中,比如将文档以嵌入方式写入向量数据库等。

抽取(Extract)
DocumentReader从源数据加载文档到内存中,源码如下:
public interface DocumentReader extends Supplier<List<Document>> {
default List<Document> read() {
return (List)this.get();
}
}实现Supplier里面的get()接口。
Spring AI内置了多种DocumentReader实现类
JsonReader:读取JSON文档
TextReader:读取纯文本文件
MarkdownReader: 读取Markdown 文件
PDFReader:读取PDF文档,基于Apache PdfBox库实现
- PagePdfDocumentReader:按照分页读取 PDF
- ParagraphPdfDocumentReader: 按照段落读取 PDF
HtmlReader:读取HTML文档,基于jsoup库实现
TikaDocumentReader:基于Apache Tika库处理多种格式的文档,更灵活
Spring AI Alibaba DocumentReader集成了更多额外的功能,例如飞书文档、email、B站视频内容解析器等等
开源仓库如果需要自定义自己的Reader,可以在官方看到源码,了解别人是如何设计的。
转换(Transform)
DocumentTransformer源码如下,实现了apply,如果需要可以自行创建符合自己的转换。
public interface DocumentTransformer extends Function<List<Document>, List<Document>> {
default List<Document> transform(List<Document> transform) {
return (List)this.apply(transform);
}
}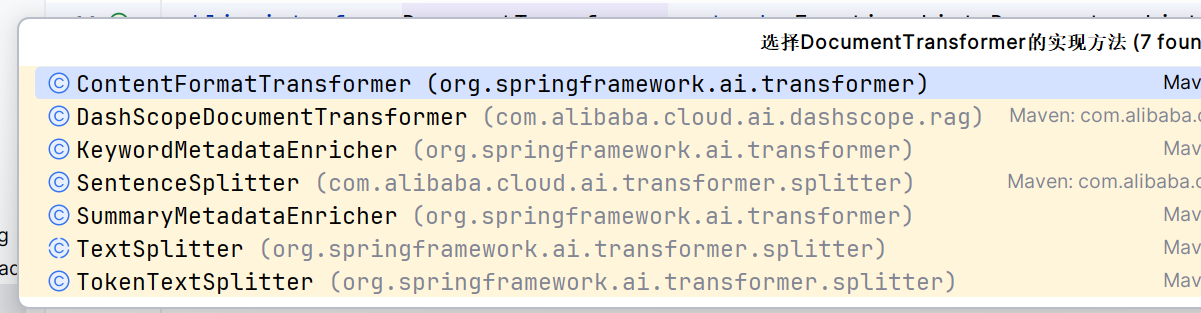
有三种转换类
- TextSplitter
- MetadataEnricher
- ContentFormatTransformer
TextSplitter文本分割器
TextSplitter是一个抽象基类,可帮助划分文档以适应 AI 模型的上下文窗口。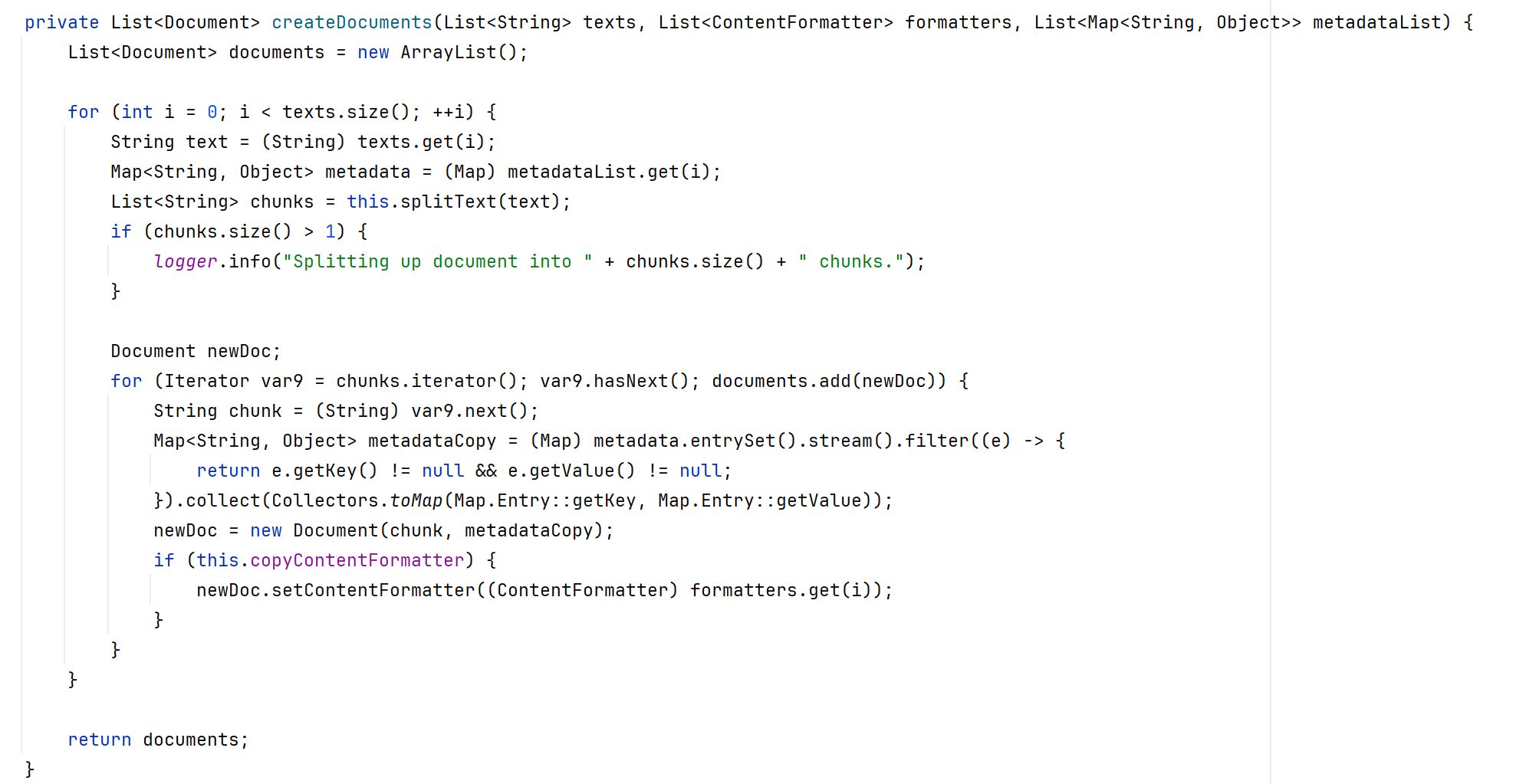
image-20250513134833089
TokenTextSplitter
TokenTextSplitter 是 TextSplitter 的一种实现,它使用 CL100K_BASE 编码根据标记计数将文本拆分为块。
这种方式考虑了语义边界。
两种使用方式,具体参数参考官方文档
@Component
class MyTokenTextSplitter {
public List<Document> splitDocuments(List<Document> documents) {
TokenTextSplitter splitter = new TokenTextSplitter();
return splitter.apply(documents);
}
public List<Document> splitCustomized(List<Document> documents) {
TokenTextSplitter splitter = new TokenTextSplitter(1000, 400, 10, 5000, true);
return splitter.apply(documents);
}
}defaultChunkSize:标记中每个文本块的目标大小(默认值:800)。minChunkSizeChars:每个文本块的最小大小(以字符为单位)(默认值:350)。minChunkLengthToEmbed:要包含的块的最小长度(默认值:5)。maxNumChunks:要从文本生成的最大块数(默认值:10000)。keepSeparator:是否在块中保留分隔符(如换行符)(默认值:true)。
Token分词器原理
使用CL100K_BASE编码将输入文本编码为token。
根据defaultChunkSize将编码后的文本分割成块。
对于每个块:
- 将块解码回文本。
- 尝试在minChunkSizeChars 之后找到合适的断点(句号、问号、感叹号或换行符)。
- 如果找到断点,则在该点截断块。
- 修剪块并根据keepSeparator 设置选择性地删除换行符。
- 如果生成的块长度大于minChunkLengthToEmbed,则将其添加到输出中。
这个过程会一直持续到所有token都被处理完或达到maxNumChunks 为止。
如果剩余文本长度大于minChunkLengthToEmbed,则会作为最后一个块添加。
MetadataEnricher源数据增强器
- KeywordMetadataEnricher:使用AI提取关键词并添加到元数据
- SummaryMetadataEnricher:使用AI生成文档摘要并添加到元数据。不仅可以为当前文档生成摘要,还能关联前一 个和后一个相邻的文档,让摘要更完整。
@Component
class MyDocumentEnricher {
private final ChatModel chatModel;
MyDocumentEnricher(ChatModel chatModel) {
this.chatModel = chatModel;
}
// 关键词元信息增强器
List<Document> enrichDocumentsByKeyword(List<Document> documents) {
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(this.chatModel, 5);
return enricher.apply(documents);
}
// 摘要元信息增强器
List<Document> enrichDocumentsBySummary(List<Document> documents) {
SummaryMetadataEnricher enricher = new SummaryMetadataEnricher(chatModel,
List.of(SummaryType.PREVIOUS, SummaryType.CURRENT, SummaryType.NEXT));
return enricher.apply(documents);
}
}- ContentFormatTransformer格式转换
加载(Load)
DocumentWriter实现了write接口
public interface DocumentWriter extends Consumer<List<Document>> {
default void write(List<Document> documents) {
this.accept(documents);
}
}有如下实现类
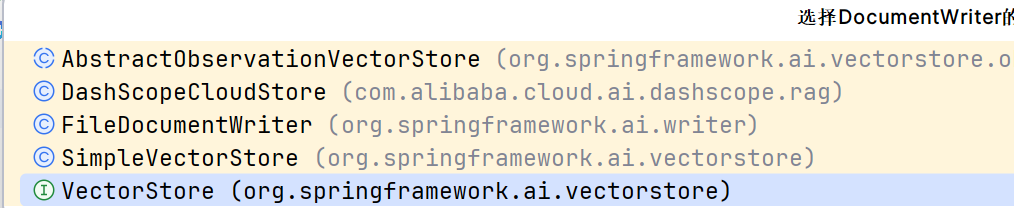
主要分成两类
- File 文件
它将 Document 对象列表的内容写入文件中
@Component
class MyDocumentWriter {
public void writeDocuments(List<Document> documents) {
FileDocumentWriter writer = new FileDocumentWriter("output.txt", true, MetadataMode.ALL, false);
writer.accept(documents);
}
}- VectorStore 矢量存储
流程组合示例
// 抽取:从 PDF 文件读取文档
PDFReader pdfReader = new PagePdfDocumentReader("xx.pdf");
List<Document> documents = pdfReader.read();
// 转换:分割文本并添加摘要
TokenTextSplitter splitter = new TokenTextSplitter(500, 50);
List<Document> splitDocuments = splitter.apply(documents);
SummaryMetadataEnricher enricher = new SummaryMetadataEnricher(chatModel,
List.of(SummaryType.CURRENT));
List<Document> enrichedDocuments = enricher.apply(splitDocuments);
// 加载:写入向量数据库
vectorStore.write(enrichedDocuments);
// 或者使用链式调用
vectorStore.write(enricher.apply(splitter.apply(pdfReader.read())));向量转换和存储
Vector
实现了DocumentWriter
public interface VectorStore extends DocumentWriter {
default String getName() {
return this.getClass().getSimpleName();
}
void add(List<Document> documents);
void delete(List<String> idList);
void delete(Filter.Expression filterExpression);
default void delete(String filterExpression) { ... };
List<Document> similaritySearch(String query);
List<Document> similaritySearch(SearchRequest request);
default <T> Optional<T> getNativeClient() {
return Optional.empty();
}
}基本上就是增、删、查三个操作
- 添加文档到向量数据库
- 删除指定文档对应的向量数据
- 相似度查询
构建请求
SearchRequest request = SearchRequest.builder()
.query("xxxxx")
.topK(10) // 返回最相似的10个结果
.similarityThreshold(0.7) // 相似度阈值,0.0-1.0之间
.filterExpression("date > '2025-05-03'") // 过滤表达式
.build();
List<Document> results = vectorStore.similaritySearch(request);工作流程
嵌入转换:当文档被添加到向量存储时,Spring Al会使用嵌入模型将文本转换为向量。
相似度计算:查询时,查询文本同样被转换为向量,然后系统计算此向量与存储中所有向量的相似度。
相似度度量:常用的相似度计算方法包括:
- 余弦相似度:计算两个向量的夹角余弦值,范围在-1到1之间
- 欧氏距离:计算两个向量间的直线距离
- 点积:两个向量的点积值
过滤与排序:根据相似度阈值过滤结果,并按相似度排序返回最相关的文档
支持的向量数据库
https://docs.spring.io/spring-ai/reference/api/vectordbs.html
可以使用Spring AI Alibaba里面内置的Vector
文档过滤和检索
https://docs.spring.io/spring-ai/reference/api/retrieval-augmented-generation.html#_pre_retrieval
文档过滤阶段分成三个阶段:预检索( Pre-Retrieval)、检索中(Retrieval)、检索后(Post-Retrieval)
- 预检索阶段,系统接收用户的原始查询,通过查询转换和查询扩展等方法对其进行优化,输出增强的用户查询。
- 检索阶段,系统使用增强的查询从知识库中搜索相关文档,可能涉及多个检索源的合并,最终输出一组相关文档。
- 检索后阶段,系统对检索到的文档进行进一步处理,包括排序、选择最相关的子集以及压缩文档内容,输出经过优 化的相关文档集。
预检索(优化用户查询)
预检索模块负责处理用户查询以实现最佳检索结果。
查询转换-查询重写(QueryTransformer)
当用户查询冗长、不明确或包含不相关信息时,此转换器非常有用 这可能会影响搜索结果的质量。
Query query = new Query("xxxxx");
QueryTransformer queryTransformer = RewriteQueryTransformer.builder()
.chatClientBuilder(chatClientBuilder)
.build();
Query transformedQuery = queryTransformer.transform(query);
通过源码可以了解实际上是写了一个Prompt,重构提示词。
查询转换-查询压缩(CompressionQueryTransformer )
使用大型语言模型来压缩对话历史记录和后续查询 转换为捕获对话本质的独立查询。
Query query = Query.builder()
.text("And what is its second largest city?")
.history(new UserMessage("What is the capital of Denmark?"),
new AssistantMessage("Copenhagen is the capital of Denmark."))
.build();
QueryTransformer queryTransformer = CompressionQueryTransformer.builder()
.chatClientBuilder(chatClientBuilder)
.build();
Query transformedQuery = queryTransformer.transform(query);查询转换-查询翻译(TranslationQueryTransformer)
大型语言模型将查询转换为支持的目标语言
Query query = new Query("Hvad er Danmarks hovedstad?");
QueryTransformer queryTransformer = TranslationQueryTransformer.builder()
.chatClientBuilder(chatClientBuilder)
.targetLanguage("english")
.build();
Query transformedQuery = queryTransformer.transform(query);查询扩展-多查询扩展(MultiQueryExpander)
用于将输入查询扩展为查询列表
MultiQueryExpander queryExpander = MultiQueryExpander.builder()
.chatClientBuilder(chatClientBuilder)
.numberOfQueries(3)
.build();
List<Query> queries = queryExpander.expand(new Query("How to run a Spring Boot app?"));系统Prompt预设:首先查询扩展,然后进行分隔
You are an expert at information retrieval and search optimization.Your task is to generate {number} different versions of the given query.Each variant must cover different perspectives or aspects of the topic,while maintaining the core intent of the original query. The goal is to expand the search space and improve the chances of finding relevant information.Do not explain your choices or add any other text.Provide the query variants separated by newlines.Original query: {query}Query variants:");检索(提高查询相关性)
从存储中搜索出相关的文档。
文档搜索
Spring AI提供了多个文档检索器,如VectorStoreDocumentRetriever、DashScopeDocumentRetriever
DocumentRetriever retriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.similarityThreshold(0.73)
.topK(5)
.filterExpression(new FilterExpressionBuilder()
.eq("genre", "fairytale")
.build())
.build();
List<Document> documents = retriever.retrieve(new Query("What is the main character of the story?"));文档合并
ConcatenationDocumentJoiner文档合并器,通过连接操作,将基于多个查询和来自多个数据源检索到的 文档合并成单个文档集合。在遇到重复文档时,会保留首次出现的文档,每个文档的分数保持不变。
Map<Query, List<List<Document>>> documentsForQuery = ...
DocumentJoiner documentJoiner = new ConcatenationDocumentJoiner();
List<Document> documents = documentJoiner.join(documentsForQuery);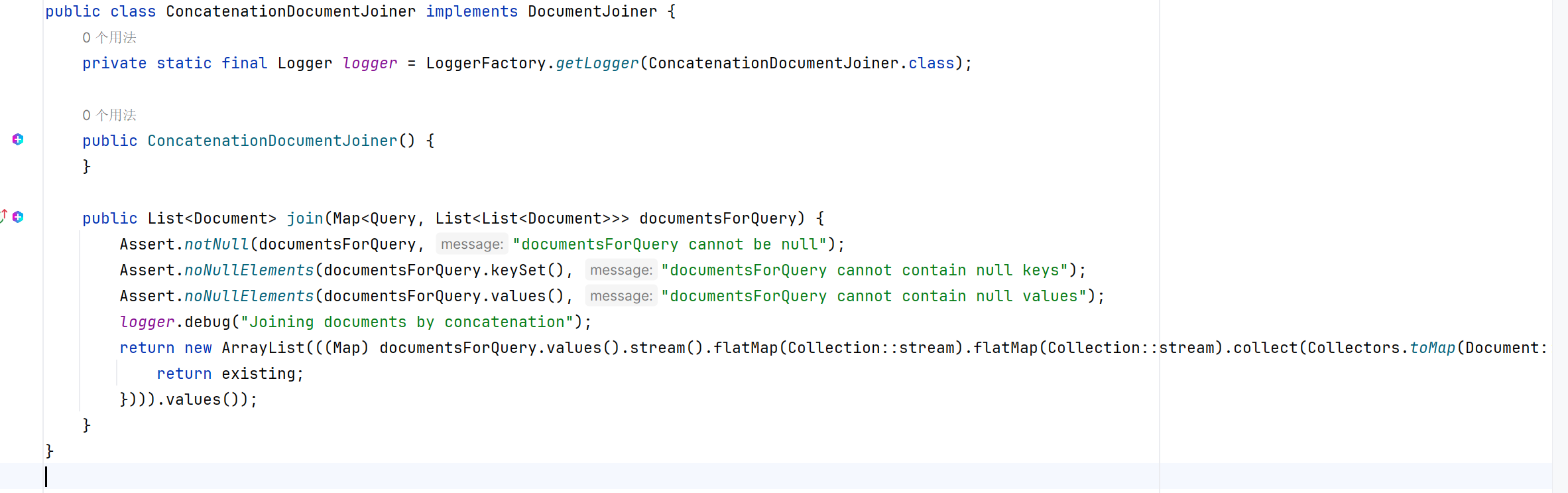
本质上就是二维数组打平,重新将一维数组合并
检索后
根据检索出来的文档,实现最佳的生成结果。可以减少信息的冗余,优化信息等。
查询增强和关联
QuestionAdvisor查询增强
用户提问,Advisor会将用户提问的向量查询向量数据库获取相应的文档,将这些文档写入上下文中。
ChatResponse response = ChatClient.builder(chatModel)
.build().prompt()
.advisors(new QuestionAnswerAdvisor(vectorStore))
.user(userText)
.call()
.chatResponse();还可以创建阈值和返回数量
var qaAdvisor = QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(SearchRequest.builder().similarityThreshold(0.8d).topK(6).build())
.build();支持动态筛选
String content = this.chatClient.prompt()
.user("Please answer my question XYZ")
.advisors(a -> a.param(QuestionAnswerAdvisor.FILTER_EXPRESSION, "type == 'Spring'"))
.call()
.content();RetrievalAugmentationAdvisor
Spring AI 包括一个 RAG 模块库 ,您可以使用这些模块来构建自己的 RAG 流。RetrievalAugmentationAdvisor 是一个 Advisor,它基于模块化架构为最常见的 RAG 流提供开箱即用的实现
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
.build();
String answer = chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user(question)
.call()
.content();ContextualQueryAugmenter
不允许检索的上下文为空。当没有查询到指定文件,不允许模型回答用户问题,防止模型没有准确信息回复错误内容。
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
.queryAugmenter(ContextualQueryAugmenter.builder()
.allowEmptyContext(true)
.build())
.build();RAG最佳实践和调优
文档收集和切割
优化原始文档
知识完备性是文档质量的首要条件。如果知识库缺失相关内容,大模型将无法准确回答对应问题。我们需要通过收集用 户反馈或统计知识库检索命中率,不断完善和优化知识库内容。
在知识完整的前提下,我们要注意3个方面:
1)内容结构化:
- 原始文档应保持排版清晰、结构合理,如案例编号、项目概述、设计要点等
- 文档的各级标题层次分明,各标题下的内容表达清晰
- 列表中间的某一条之下尽量不要再分级,减少层级嵌套
2)内容规范化:
- 语言统一:确保文档语言与用户提示词一致(比如英语场景采用英文文档),专业术语可进行多语言标注
- 表述统一:同一概念应使用统一表达方式(比如ML、Machine Learning 规范为“机器学习”),可通过大模型分段处 理长文档辅助完成
- 减少噪音:尽量避免水印、表格和图片等可能影响解析的元素
3)格式标准化:
- 优先使用Markdown、DOC/DOCX等文本格式(PDF解析效果可能不佳)
- 如果文档包含图片,需链接化处理,确保回答中能正常展示文档中的插图,可以通过在文档中插入可公网访问的URL 链接实现
文档切片
文档切片尺寸需要根据具体情况灵活调整,避免两个极端:切片过短导致语义缺失,切片过长引入无关信息。具体需结合 以下因素:
- 文档类型:对于专业类文献,增加长度通常有助于保留更多上下文信息;而对于社交类帖子,缩短长度则能更准确地 捕捉语义
- 提示词复杂度:如果用户的提示词较复杂且具体,则可能需要增加切片长度;反之,缩短长度会更为合适
最佳文档切片策略是 结合智能分块算法和人工二次校验。智能分块算法基于分句标识符先划分为段落,再根据语义相关 性动态选择切片点,避免固定长度切分导致的语义断裂。在实际应用中,应尽量让文本切片包含完整信息,同时避免包含 过多干扰信息。
元数据标注
为文档添加丰富的结构化信息,便于后续的向量化处理和精确搜索。
向量转换和存储
- 选择合适的向量存储
- 选择合适的嵌入模型
文档过滤和检索
多查询扩展
用户输入的提示词可能不完整,有歧义。可以使用多查询扩展扩大检索范围,提高文档召回率。
MultiQueryExpander queryExpander = MultiQueryExpander.builder()
.chatClientBuilder(chatClientBuilder)
.numberOfQueries(3)
.build();
List<Query> queries = queryExpander.expand(new Query("xxx"));查询重写和翻译
- TranslationQueryTransformer
- QueryTransformer
检索器配置
- 设置合理的相似度阈值
- 控制文档返回数量
- 配置文档过滤规则
@Slf4j
public class LoveAppRagCustomAdvisorFactory {
public static Advisor createLoveAppRagCustomAdvisor(VectorStore vectorStore, String status) {
Filter.Expression expression = new FilterExpressionBuilder()
.eq("status", status)
.build();
DocumentRetriever documentRetriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.filterExpression(expression) // 过滤条件
.similarityThreshold(0.5) // 相似度阈值
.topK(3) // 返回文档数量
.build();
return RetrievalAugmentationAdvisor.builder()
.documentRetriever(documentRetriever)
.build();
}
}查询增强和关联
用户提出的问题可能不存在当前RAG知识库,这时候我们需要提示用户修改提示词或者提示用户不存在相关文档,可以使用ContextualQueryAugmenter上下文查询增强
public class LoveAppContextualQueryAugmenterFactory {
public static ContextualQueryAugmenter createInstance() {
PromptTemplate emptyContextPromptTemplate = new PromptTemplate("""xxxx""");
return ContextualQueryAugmenter.builder()
.allowEmptyContext(false)
.emptyContextPromptTemplate(emptyContextPromptTemplate)
.build();
}
}除了上述优化策略外,还可以考虑以下方面的改进:
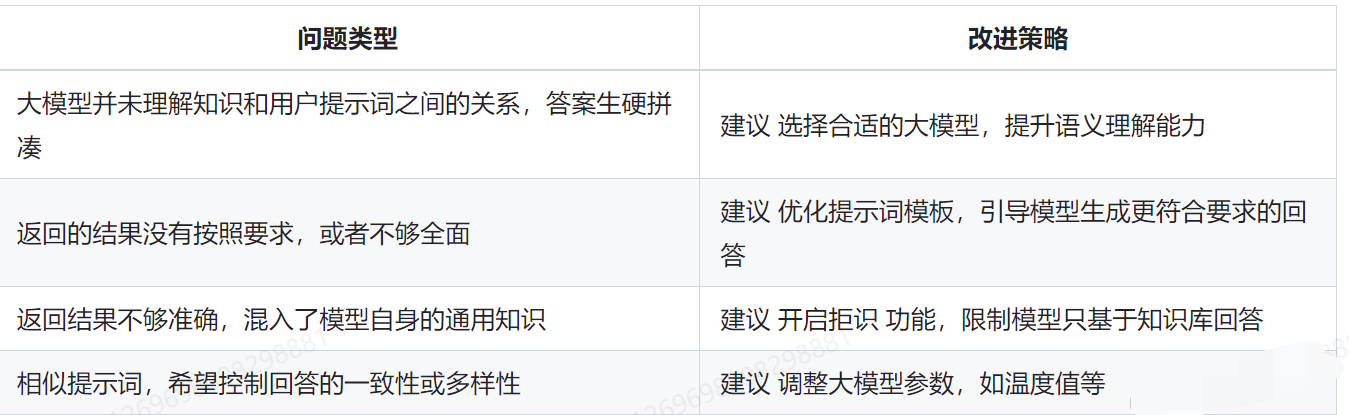
- 分离检索阶段和生成阶段的知识块
- 针对不同阶段使用不同粒度的文档,进一步提升系统性能和回答质量
- 针对查询重写、关键词元信息增强等用到AI大模型的场景,可以选择相对轻量的大模型,不一定整个项目只引入一 种大模型
混合检索策略
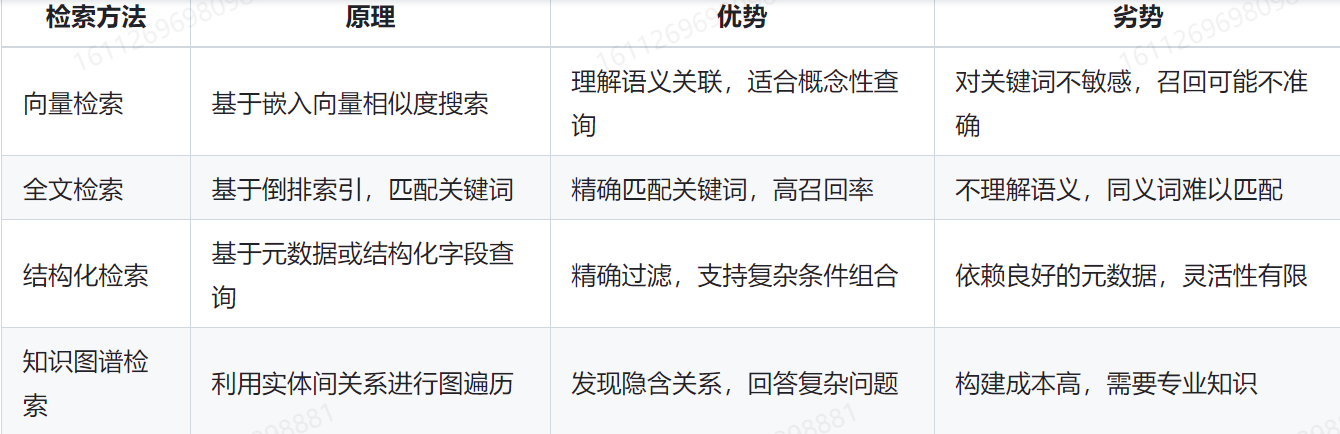
并行混合存储
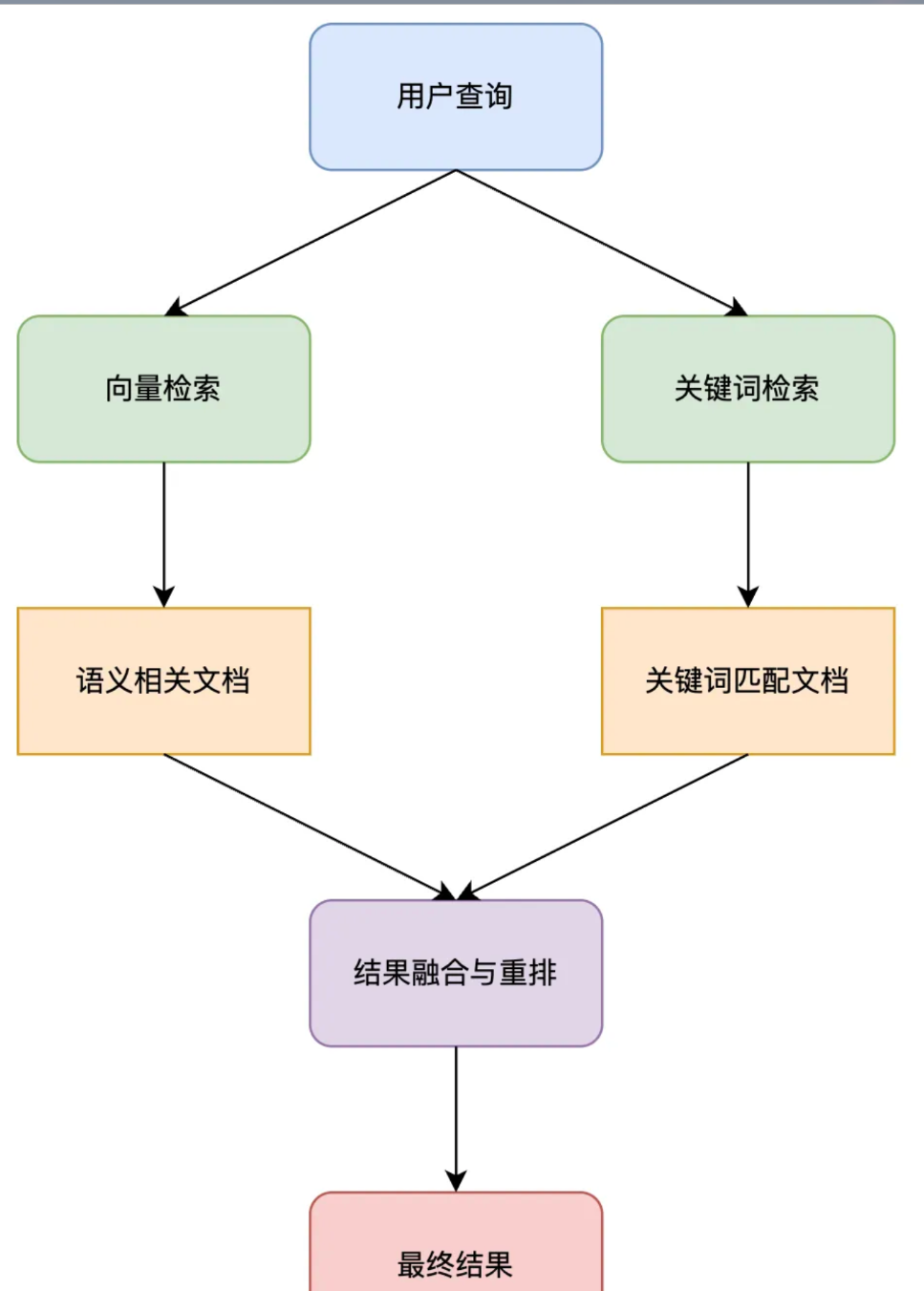
级联混合检索
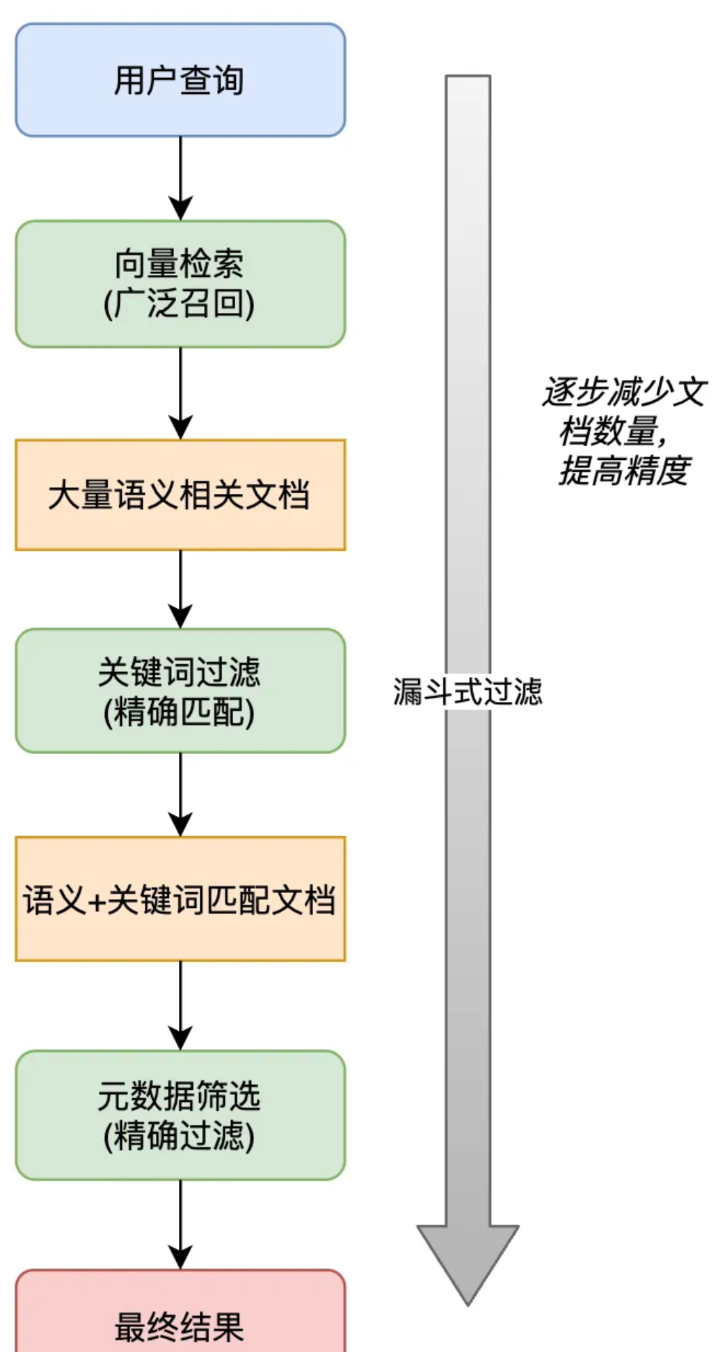
动态混合检索
大模型幻觉
- 事实性幻觉:事实不符
- 逻辑性幻觉:推理过程存在逻辑错误
- 自洽性幻觉:前后问答存在矛盾
大语言模型本质是预测下一个词的概率
解决方式如下:
- 通过引入外部知识源,我们可以让模型不再完全依赖其参数中存储的信息,而是基于检到的最新、准确的信息来回答问题。
- 有效的RAG实现通常会引入“引用标注”机制,让模型明确指出信息来源于哪个文档的哪个部分。
- 提示工程优化,可以采用“思维链”提高推理透明度,通过引导模型一步步思考,我们能够更好地观察其推理过程,及时发现可能的错误。
- 使用事实验证模型检查生成内容的准确性,建立关键信息的自动核查机制,或实施人机协作的审核流程。评估幻觉程度的指标包括事实一致性、引用准确性和自洽性评分。
RAG应用评估
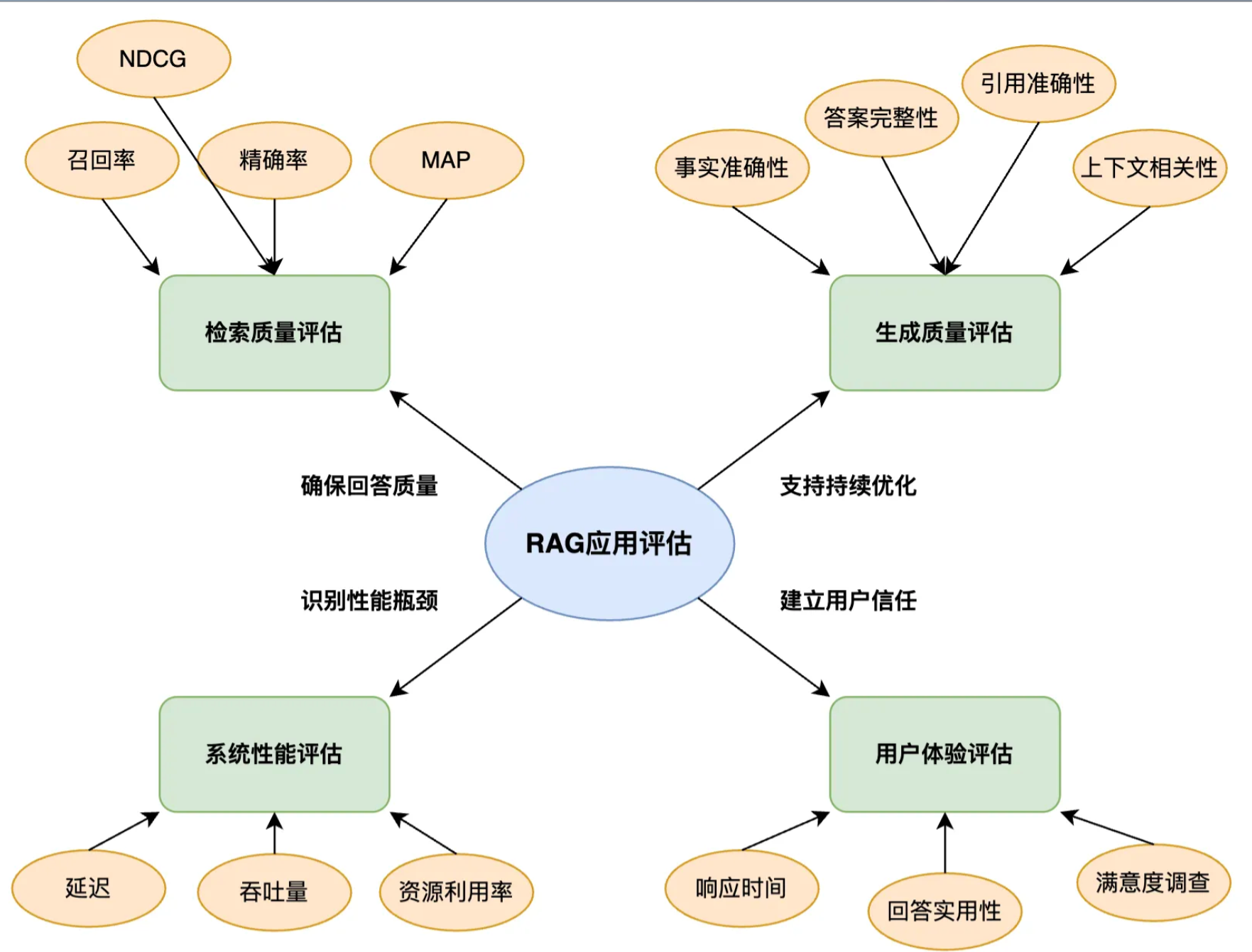
RAG架构
自纠错RAG(C-RAG)
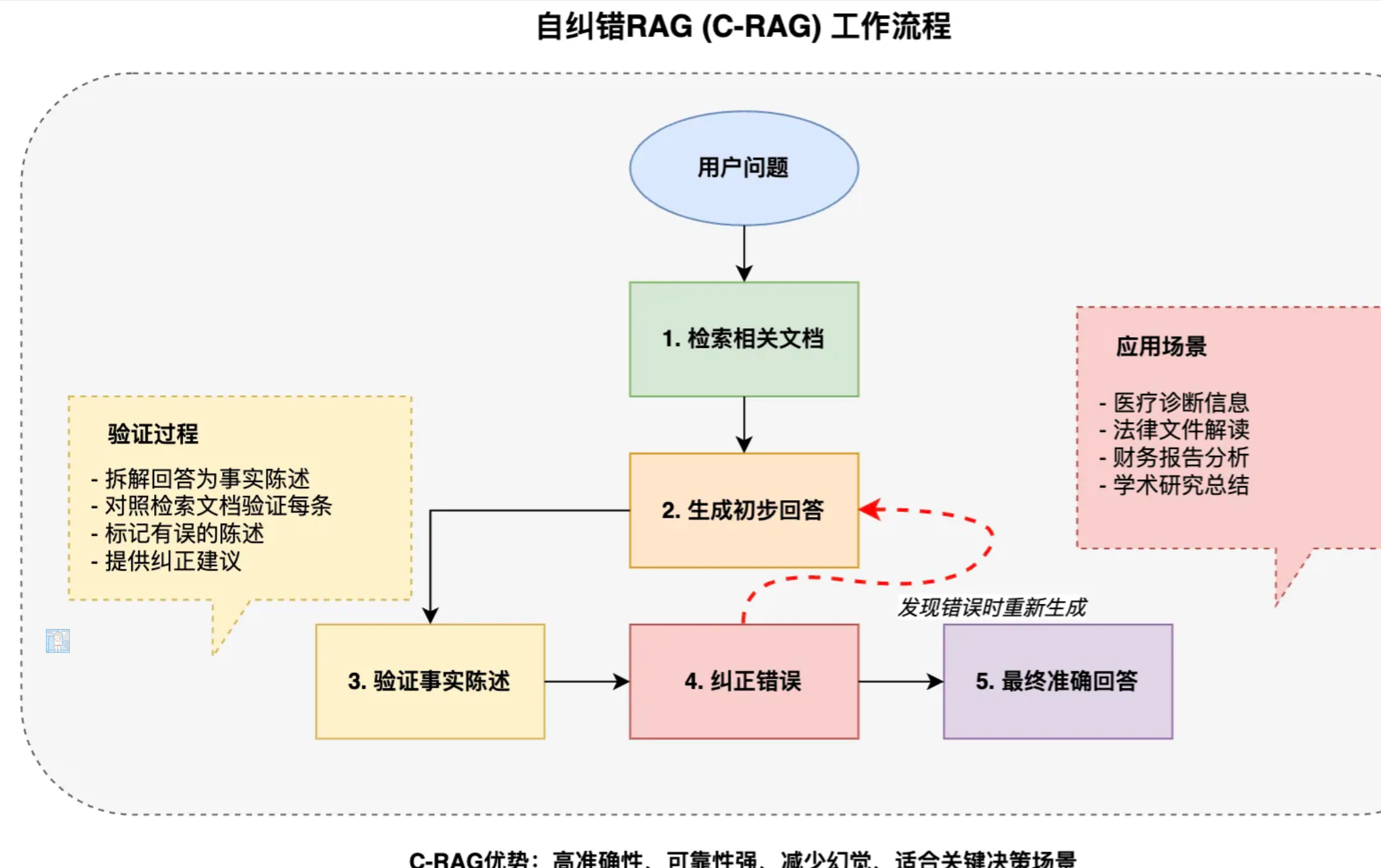
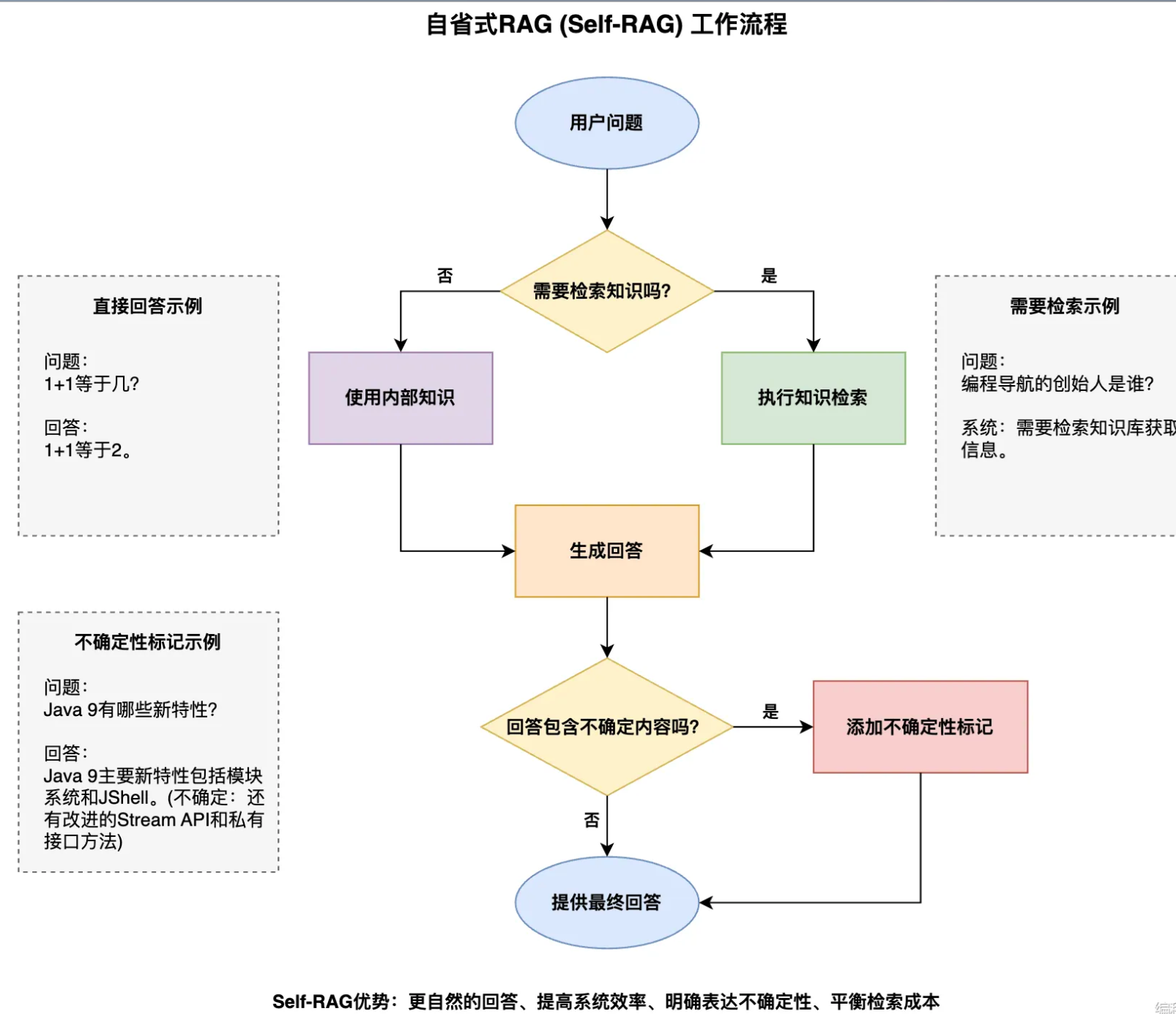
自省RAG(Sefl-RAG)
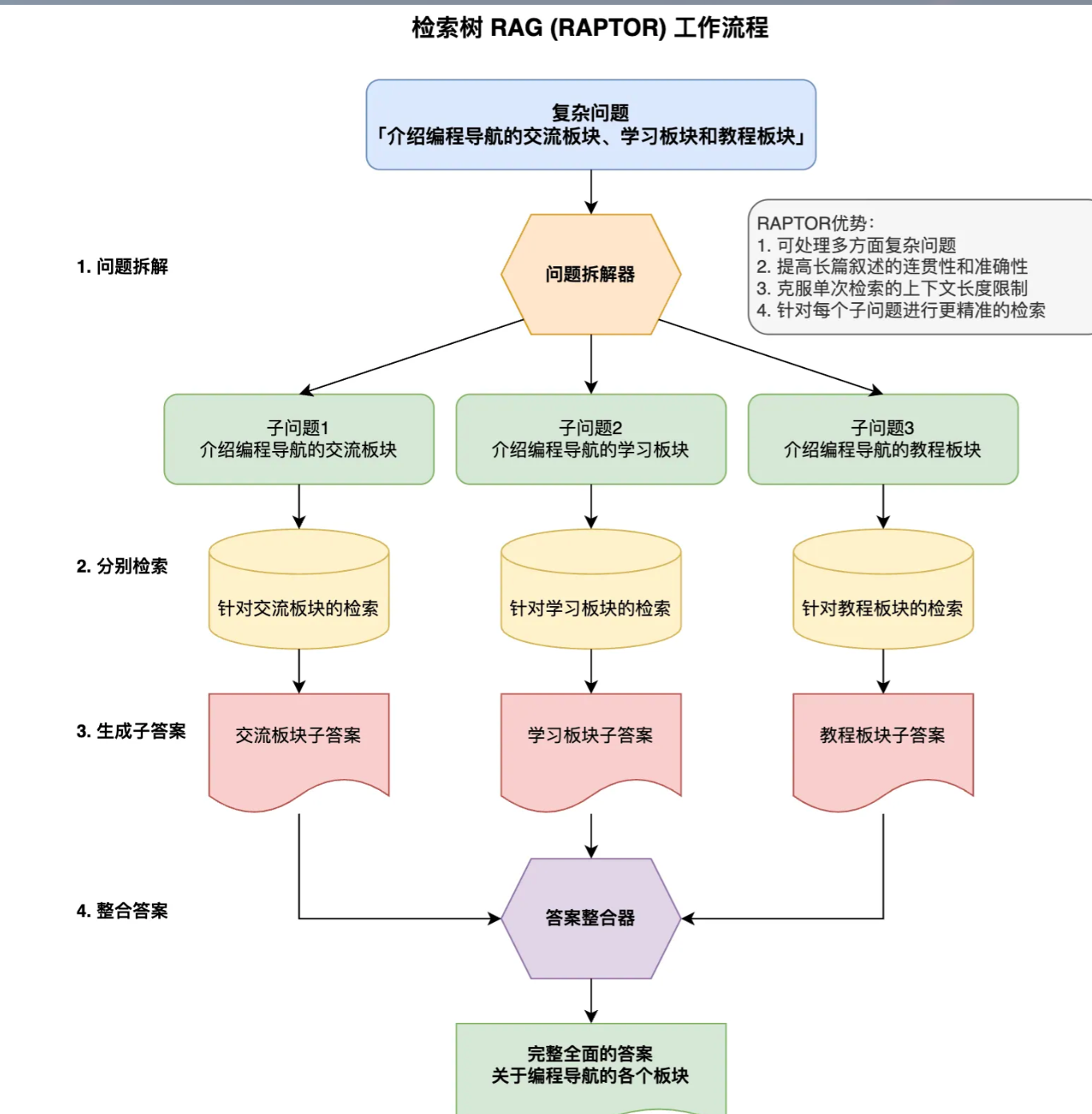
检索树RAG
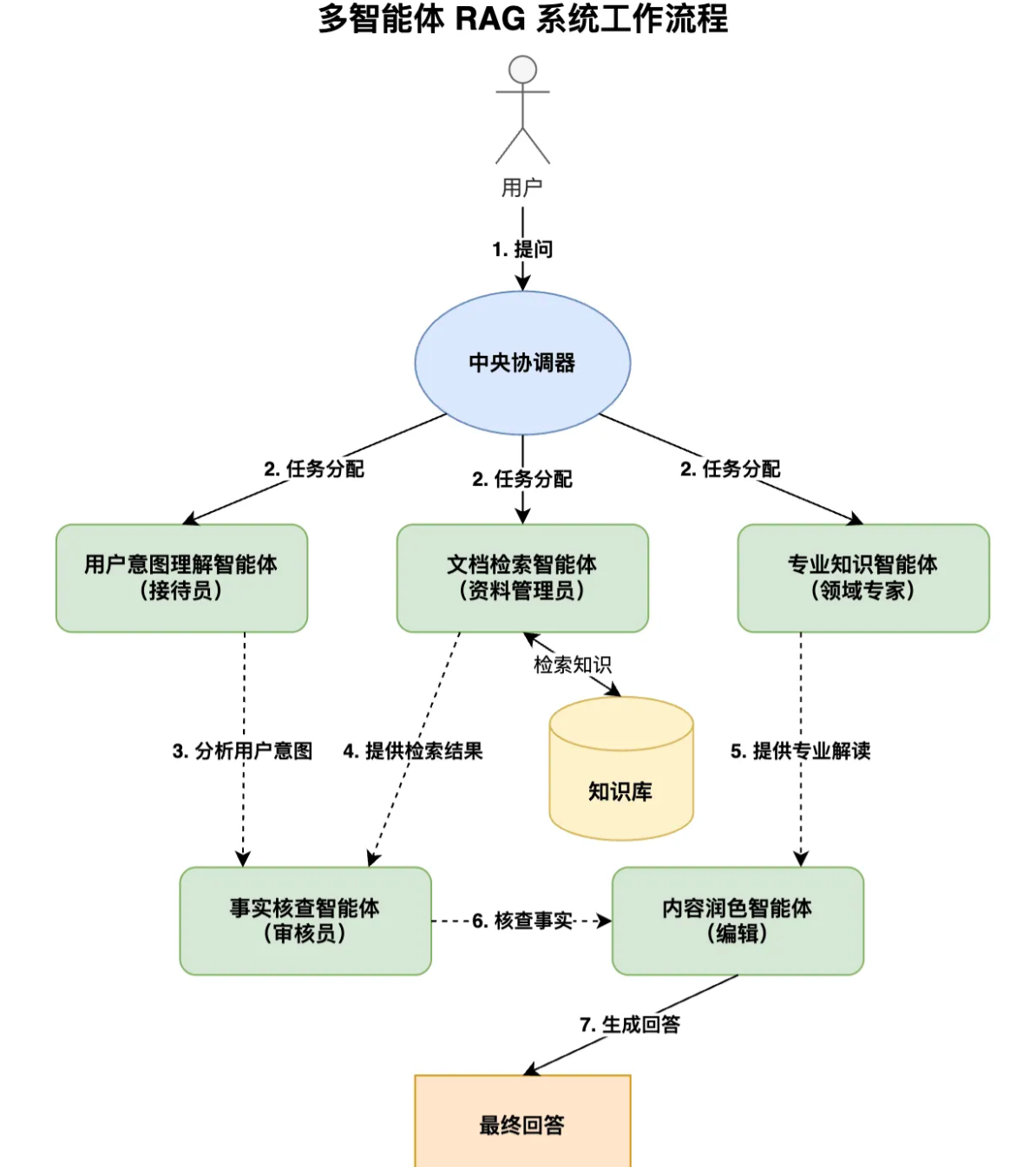
多智能体RAG系统
贡献者
flycodeu
版权所有
版权归属: