Tesseract使用
Tesseract 是一款高精度的开源 OCR(Optical Character Recognition,光学字符识别)引擎,能够将图片或扫描文档中的文本内容提取为可编辑文字数据。 该引擎支持多语言识别(包括中文、英文、日文等),可通过命令行使用,也可在 Python、C++、Java 等语言中以 API 形式集成。
- 官方文档: https://tesseract-ocr.github.io/tessdoc/#introduction
- 源码仓库: https://github.com/tesseract-ocr/tesseract
📦 一、安装与环境配置
✅ 官方安装包(推荐方式)
下载地址: 👉 https://github.com/tesseract-ocr/tesseract/releases
下载安装包(.exe)后运行即可快速完成安装。支持自定义路径及免安装模式。
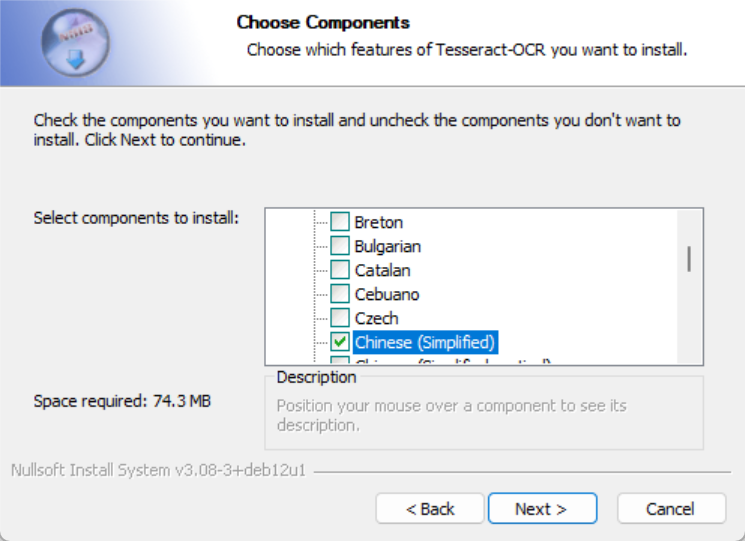
安装过程中可选择所需语言包:
🧭 配置系统环境变量
记录安装目录,例如:
D:\Developer Tools\TesseractOcr在系统「环境变量」中,将上述路径加入
Path。
完成后,在命令行验证安装:
tesseract --version若返回如下信息,则说明安装成功:
tesseract v5.5.0.20241111
leptonica-1.85.0
Found libcurl/8.11.0 ...⚠️ 若命令无效,请尝试重新启动计算机。
💡 二、使用 Chocolatey 一键安装(Windows)
如果你偏好命令行环境,可使用 Chocolatey 包管理器快速部署:
1️⃣ 安装 Chocolatey
以管理员模式运行 PowerShell,执行以下命令:
Set-ExecutionPolicy Bypass -Scope Process -Force; `
[System.Net.ServicePointManager]::SecurityProtocol = `
[System.Net.SecurityProtocolType]::Tls12; `
iex ((New-Object Net.WebClient).DownloadString('https://community.chocolatey.org/install.ps1'))2️⃣ 安装 Tesseract
choco install tesseract3️⃣ 命令行识别示例
tesseract "input.jpg" "output" -l enginput.jpg:输入图像文件output:输出文本文件名(无需扩展名)-l eng:使用英文语言模型
识别结果将保存为 output.txt。
🧱 三、源码编译(开发者向)
⚠️ 一般用户无需自行编译,建议直接使用官方安装包。
1️⃣ 构建依赖
- Visual Studio Build Tools 或 MinGW-w64
- CMake ≥ 3.20
2️⃣ 生成构建文件
cd your-tesseract-folder
mkdir build && cd build
cmake ..3️⃣ 编译
cmake --build . --config Release构建完成后,build/bin 目录下会生成 tesseract.exe。
🌍 四、语言包(tessdata)配置
Tesseract 默认仅包含英文识别模型。若需支持中文等其他语言,请手动下载对应的 .traineddata 模型文件。
下载地址: 👉 https://github.com/tesseract-ocr/tessdata
示例:添加简体中文支持
下载
chi_sim.traineddata放入以下目录:
C:\Program Files\Tesseract-OCR\tessdata\命令行测试:
tesseract input.jpg output -l chi_sim
🧩 五、Python 集成(pytesseract)
在完成 Tesseract 安装后,推荐通过 pytesseract 模块在 Python 中调用 OCR 功能。
1️⃣ 安装依赖
pip install pytesseract pillowpytesseract:Tesseract 的 Python 封装Pillow:图像处理与加载库
确认命令行中可执行 tesseract --version。
2️⃣ 基础英文识别
import pytesseract
from PIL import Image
image = Image.open("example.jpg")
text = pytesseract.image_to_string(image, lang="eng")
print(text)3️⃣ 中文及中英文混合识别
import pytesseract
from PIL import Image
image = Image.open("chinese_text.png")
text = pytesseract.image_to_string(image, lang="chi_sim+eng")
print(text)请确保
chi_sim.traineddata文件已放置于tessdata目录。
4️⃣ 指定 Tesseract 可执行路径(可选)
若未设置系统 PATH,可在代码中显式指定:
pytesseract.pytesseract.tesseract_cmd = r'D:\Developer Tools\TesseractOcr\tesseract.exe'5️⃣ OCR 识别与结果输出
import pytesseract
from PIL import Image
image = Image.open("test.png")
text = pytesseract.image_to_string(image, lang="chi_sim+eng")
with open("output.txt", "w", encoding="utf-8") as f:
f.write(text)
print("识别结果:\n", text)6️⃣ 效果示例
📄 六、从 PDF 提取文字(合同识别场景)
场景说明
用户上传多页 PDF(如合同、扫描件),需自动识别并输出 .txt 文本文件。 此场景通常需先将 PDF 转换为图片,再执行 OCR。
方案一:使用 Poppler(推荐)
1️⃣ 下载 Poppler for Windows
GitHub 地址: 👉 https://github.com/oschwartz10612/poppler-windows/releases/
下载预编译版本(如 poppler-24.08.0_x64.7z)并解压到:
D:\Developer Tools\poppler-24.08.02️⃣ 配置 PATH
将以下路径添加至系统环境变量:
D:\Developer Tools\poppler-24.08.0\Library\bin3️⃣ 验证安装
pdfinfo -h
pdftoppm -h若输出 usage 信息,则配置成功。
方案二:免安装 Poppler(使用 PyMuPDF)
无需外部依赖,性能更优:
pip install pymupdf示例代码(支持中文 PDF)
import os
import pytesseract
from pdf2image import convert_from_path
TESSERACT_CMD = r'D:\Developer Tools\TesseractOcr\tesseract.exe'
POPPLER_PATH = r'D:\Developer Tools\poppler-25.07.0\Library\bin'
pytesseract.pytesseract.tesseract_cmd = TESSERACT_CMD
def pdf_to_text(pdf_path, output_txt_path, lang='chi_sim', dpi=300):
if not os.path.exists(pdf_path):
raise FileNotFoundError(f"PDF 文件不存在: {pdf_path}")
print("📄 正在将 PDF 转换为图像...")
images = convert_from_path(pdf_path, dpi=dpi, poppler_path=POPPLER_PATH)
full_text = ""
for page_num, img in enumerate(images, start=1):
print(f"🔍 正在识别第 {page_num} 页...")
text = pytesseract.image_to_string(
img,
lang=lang,
config='--psm 6 --oem 3 -c preserve_interword_spaces=1'
)
full_text += f"\n=== 第{page_num}页 ===\n{text.strip()}\n"
with open(output_txt_path, 'w', encoding='utf-8') as f:
f.write(full_text)
print(f"✅ OCR 完成!结果保存至: {os.path.abspath(output_txt_path)}")
if __name__ == "__main__":
pdf_to_text(
pdf_path=r"xxxx.pdf",
output_txt_path="识别结果.txt",
lang='chi_sim',
dpi=300
)若不使用 Poppler,可改用
fitz(PyMuPDF)实现同样功能,兼容加密 PDF 与文本提取。
🧪 七、常见问题排查
| 问题 | 解决方案 |
|---|---|
TesseractNotFoundError | 未安装 Tesseract 或路径未配置 → 在代码中设置 tesseract_cmd |
| 输出为空或乱码 | 缺少语言包 → 下载相应 .traineddata 文件放入 tessdata |
| 中文识别错误或偏移 | 使用简体中文模型 chi_sim,或调整 DPI(建议 200–300) |
| 图片模糊导致识别率低 | 使用 OpenCV 或 Pillow 进行图像预处理(如二值化、锐化、去噪) |
✅ 八、总结与最佳实践
| 使用场景 | 推荐方案 |
|---|---|
| 快速命令行文字识别 | ✅ 直接使用官方安装包或 Chocolatey |
| Python 自动化处理 | ✅ 使用 pytesseract + poppler |
| PDF 合同或多页扫描件 OCR | ✅ 结合 pdf2image 或 fitz 模块 |
| 自行编译或二次开发 | ⚙️ 仅限高级用户,建议使用 CMake 构建 |
结论: 对于绝大多数 Windows 用户,推荐直接从 👉 Tesseract Releases 下载稳定版安装包,结合 pytesseract 及 Poppler 即可实现高质量中英文 OCR 识别,无需手动编译源码。
贡献者
flycodeu
版权所有
版权归属: